
An end-of-year look at theories of everything
Theories of everything, everywhere, all at once

It’s been a whirlwind year in NeuroAI. I have over 250 papers saved up in a folder in Zotero of NeuroAI papers I saw fly by in 2023–and that doesn’t include all the NeurIPS papers that came out this December. It was the ballooning of this folder–as well as the imminent collapse of Twitter/X–that motivated me to start this newsletter in August. Rather than a traditional end-of-year review, as I did in 2021 and 2022, I decided to take on a more meta route and discuss some theories of everything in neuroscience and AI. I hope you have a wonderful New Year with friends and loved ones and I’ll see you in 2024 🎉 🍾
Theories of everything in neuroscience
Why are we here? What are brains for? What is intelligence? Given looming deadlines and an ever-growing to-do list, it’s hard to think deeply about these things for more than a couple of hours at a time. I decided to take some time over the holidays to think deeply about these issues.
I was excited to pour over A Brief History of Intelligence by Max Bennett. It was recommended by Dileep George, who wrote one of the blurbs, and more recently by Richard Sutton (of RL and Bitter Lesson fame). I’ve been enjoying this breezy, narrative history of intelligence. The author uses the history of early bilaterians, vertebrates, mammals, primates, and humans to craft a narrative around how cognitive capacities, neural structures, body plans and environments co-evolved to create adaptive behaviours.
One example of these ideas is our urbilaterian ancestor, a worm-like creature not too dissimilar from a modern C. elegans. This worm was a swimmer engaged in finding food and avoiding predators. This lifestyle encouraged the appearance of centralized, fused ganglia to maintain a consistent internal state; i.e. a brain. In a hungry state, the worm would be more explorative, even though this would mean it was more exposed to predators; if it was satiated, it would stop moving to conserve its energy. Various signals emerged to carry these states, of approach and avoidance, of stress and relaxation, ancestors to what we would eventually come to be called emotions. And with this short-term state could come adaptive behaviours, such that a stimulus does not always lead to the same response, depending on the state of the animal. Link the environment and outcomes and you can have reinforcement of particular behaviours. Thus, a sensorimotor loop, emotions, and learning were preserved and built upon in vertebrates to come.

The book is conceptually aligned with the idea of phylogenetic refinement as advanced by Paul Cisek. Phylogenetic refinement is a process where the brain's structure and functionality are shaped not only by individual development (ontogeny) but also by the evolutionary history of the species (phylogeny). Current brain functions have evolved from simpler forms present in ancestral species, and these functions have been refined over evolutionary time. In other words, nothing in biology makes sense except in light of evolution. It’s an example of a theory of brains with wide explanatory power.
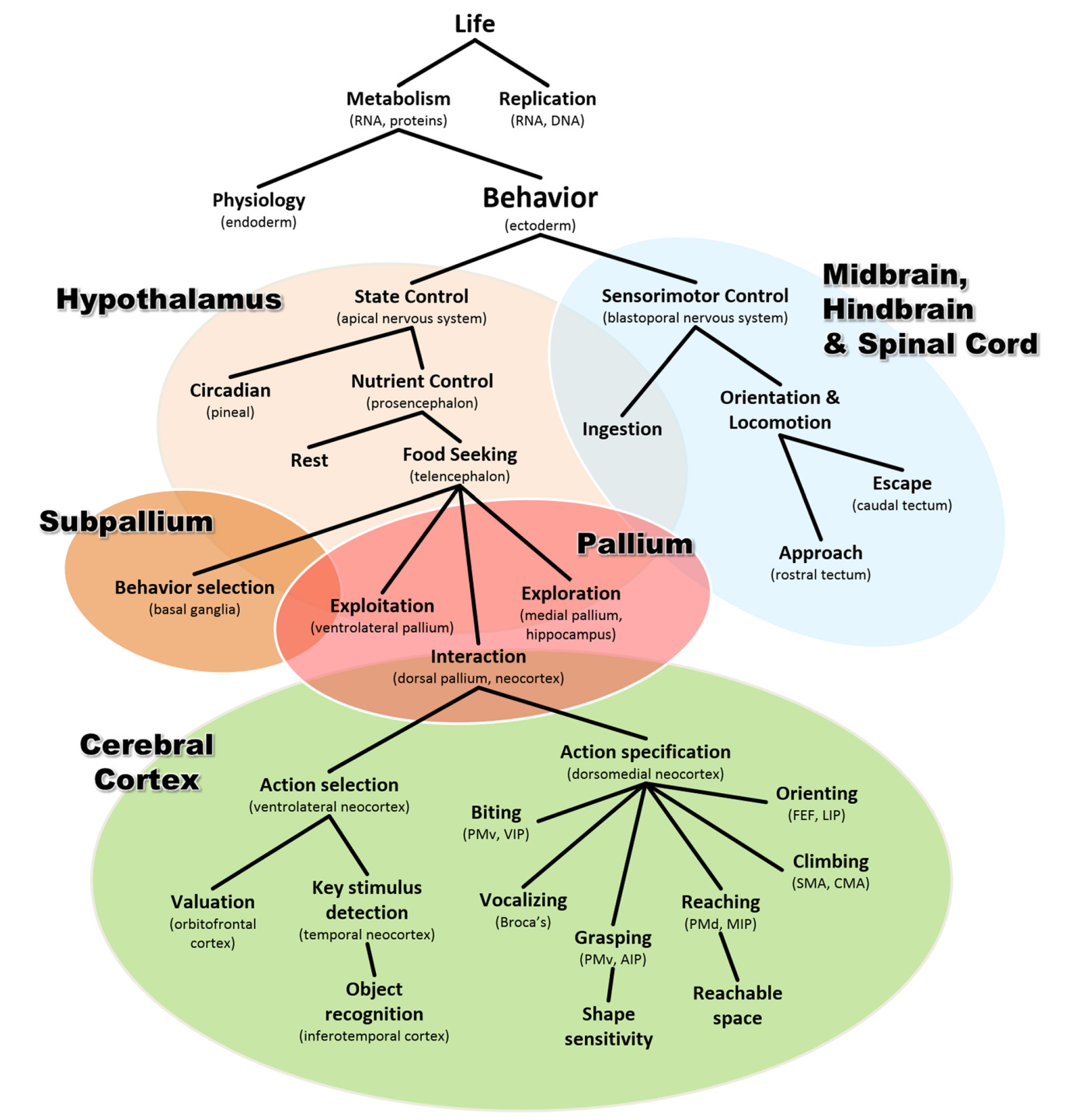
I like this framing both from an explanatory point of view and as a roadmap to practically embed intelligence in artificial systems. An enterprising person might take a look at the functions or areas captured by these theories and instantiate them in a mechanistic model. reflexes, imitation learning, reinforcement learning, and social learning are distinct aspects of learning complex motor programs. One might want to instantiate principles of hierarchical motor control, as implemented by the brain, to build flexible robots that don’t require perfect actuators. We can see these principles at play, for example, in this demo from Deepmind of cheap robots playing soccer.
A handful of people have taken the logic of compartmentalized, phylogenetically refined models to cover a large array of functions and areas, notably the team led by Chris Elliasmith. Perception, working memory, hierarchical motor control and reward are linked in spiking neural networks which are fast approaching the size, in terms of distinct units and number of synapses, of large language models. These are not (yet) brains in a vat, and are less capable than LLMs of the same size, but they point the way towards models that bring together multiple capabilities, in particular in terms of closing the action-perception loop.

Theories of everything, everywhere, all at once
Your average undergraduate neuroscience class can feel an awful lot like describing a stamp collection: lots of facts disconnected from the bigger picture. I like these attempts at what may be called theories-of-everything (TOE) because they allow numerous phenomena to be described coherently.
When it comes to translating natural intelligence to artificial systems, aggregating and distilling information is a crucial intermediary. The specific implementations of neural algorithms in biological neural networks may not translate one-to-one to their artificial counterparts. For one, the engineering requirements are vastly different–server farms using the energy of small cities and humans running on bananas live in very different regions of SWaP-C (size, weight, power and cost).
4 years ago, I saved this tweet from Josh Vogelstein that listed some theories of everything in neuroscience. I have made some slow and steady progress in better understanding the list–I even managed to trudge through a bit of Stephen Grossberg’s book, despite dire warnings. Josh’s list has been a source of endless inspiration.
I will concur with Surya Ganguli that many TOEs in neuroscience and on the topic of intelligence in general are “not even wrong”, in the sense of not being falsifiable. One of the sharpest examples–from a slightly distant but related field–is Legg and Hutter (2007), who introduce a universal definition of machine intelligence. This general intelligence is the weighted average reward obtained by an agent over an ensemble of environments. The weighting is given by the (negative exponential) of the Kolmogorov complexity of the environments. Kolmogorov complexity is the length of the shortest computer program that defines the environment. That weighting is eminently sensible: simpler environments are more likely and should be up-weighted. There are also many more incompressible environments (e.g. generated by a universal Turing machine seeded by a random number generator) than there are compressible environments, hence we should upweight compressible environments.
The problem, of course, is that Kolmogorov complexity is uncomputable, as a consequence of the negative resolution of the halting problem. So, their scheme is both really enlightening and utterly impractical. Talk about not even wrong: it’s not even computable! This hasn’t stopped that paper from sowing the seeds of what would later become Deepmind and foreshadowing both modern RL and LLMs. A good theory of everything should highlight some interesting underlying ideas that can be sifted through by an enterprising and discriminative AI researcher, even if the ideas are not directly presented in practical form.
Closing out the year
Part of the reason I’ve been thinking deeply about the grand scheme of things is that I’ve taken up the role of curriculum lead for the Neuromatch Academy NeuroAI course. I’ve got big shoes to fill (Konrad Kording was curriculum lead for the DL course and Gunnar Blohm for computational neuroscience), but with a kickass team led by Xaq Pitkow I know we will pull through. I want to bring a spirit of radical intellectual curiosity of discussing really big ideas, while also getting into the weeds and teaching students how to implement these ideas.
We have a pretty solid curriculum skeleton lined up and several day leads confirmed. If you’ve read this far, don’t be surprised if you get an email from me, Xaq, or projects lead Eva Dyer, to help out with the course. It’s an awesome opportunity to push our field forward and teach the next generation of neuroscience and AI weirdos.
As a parting thought for this year, I’m grateful that I get to think deeply about brains and AI for a living! I’ve had the amazing support of the Mila team and colleagues since I joined in June–we have some awesome things lined up in terms of building and releasing foundation models for neuroscience, which I’ll write about in 2024. It’s been thrilling to share my thoughts with you–growing to a bit over 500 650 subscribers in less than 6 months, a not insignificant proportion of all neuroAI researchers. Thanks for reading, and have a safe and happy New Year 🎉 🍾