
Artificial intelligence by mimicking natural intelligence
Connectomics, behavioural cloning, lo-fi and hi-fi whole-brain emulation

I had a chance to watch this seminar series and workshop from the Foresight Institute on Whole-Brain Emulation (WBE) as a path to Artificial General Intelligence (AGI). WBE is definitely out there. There are, however, some fascinating ideas I wanted to cover here. This is going to be a bit more speculative than what I usually cover, but I want to leave some breathing room for big ideas.
The idea behind WBE is appealingly simple: if you can simulate a human brain in silico in excruciating detail, you’ve got an AGI. Simulate it faster, fix the “bugs” (e.g. lower plasticity in later adulthood) and you have faster-than-human general intelligence. This field has seen cycles of hype (e.g. TED talks 1, 2) and disappointment, as captured in the wonderful film In Silico. We’re currently past a cycle of hype and have seen some real results coming from the field of connectomics.
Hi-fi paths toward WBE
Slice the brain using electron microscopy, use petascale computing to label and stitch together the slices, and you have yourself a connectome. The MiCRONS project has done this for a millimetre-cube of cortex in mice; the fly connectome has already revolutionized the study of these organisms.
Provided a connectome for a whole brain, it’s possible to simulate the model forward, using single-neuron models of varying biological plausibility, from linear-integrate-and-fire to detailed multi-compartment models with Hodgkin-Huxley dynamics. Simulate the body and environment, in addition, and you have yourself a whole-brain-body-environment simulation. We’re not there yet, but one could imagine this could happen in the not-too-distant future, especially for smaller organisms.
How well would this work? It depends on the answer to a few empirical questions. There was a recent article from Nicole Rust in The Transmitter magazine on whether the brain is chaotic, that is, whether it displays exponential sensitivity to initial conditions. If the brain displays chaos, small measurement errors in initial conditions will propagate to arbitrarily large errors over time. It’s likely that if the brain is chaotic with respect to neural activity, then it will also display exponential sensitivity to the weights of its connection matrix. Chaos is incompatible with literal whole-brain emulation, in the same way that you can’t literally predict the weather over longer periods than a couple of weeks–though you can predict the climate.
There’s also the open question of how much the static connectome can capture. Dendrites and synapses roll over; we can’t always infer the strength of a connection from its static shape; there’s ephaptic coupling and non-synaptic transmission. The latter appears to be a bit of a bottleneck in C Elegans, where recent results show that the connectome is not very predictive of neural activity.
Lo-fi paths toward WBE
When people talk about WBE, they generally refer to the connectomics route, followed by single-neuron emulation. Indeed, Anders and Bostrom1 (2008) wrote a roadmap for WBE that looks a lot like modern EM-based connectomics. What’s interesting is how they cast a formal definition of whole-brain emulation, in a footnote in the introduction:

Their definition is based on accurately predicting the future state of a brain starting from an initial state. This dynamics-based definition of whole brain emulation looks a lot like time-series forecasting or next-token prediction, in the style of GPT. With modern artificial neural networks (ANNs), direct time-series forecasting without reference to a connectome looks like an increasingly feasible way to achieve something that looks like WBE.
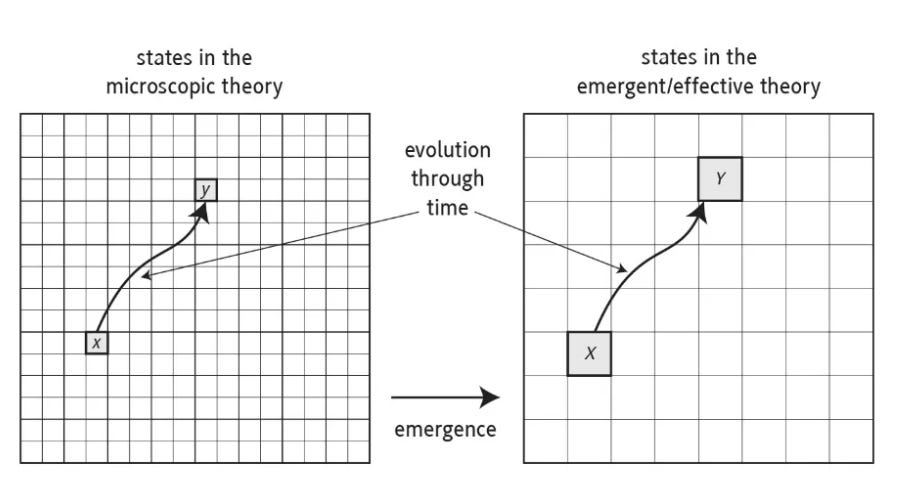
Furthermore, there is flexibility in how one defines the state. A behaviourist might focus on externally measurable variables only, e.g. the activations of all the muscle afferents of the body as well as the position of the limbs. Someone inspired by Mountcastle might care primarily about the average activity neurons in cortical columns or in mini-columns. In those cases, one reduces the state from trillion-dimensional (i.e. 86 billion neurons times all the state variables in each neuron) to anywhere from a few hundred to perhaps a billion. Bringing down the dimensionality by several orders of magnitude makes these approaches seemingly more tractable over the short term.
Several people in these Foresight Institute talks refer to these approaches as lo-fi, to distinguish them from more conventional high-fidelity, single neurons+connectome approaches. I wasn’t able to track down a written reference that uses that term–it might be a jargon term associated with that Institute, but I think it’s useful enough that I’ll use it here.
Catalin Mitelut categorizes lo-fi approaches into three buckets:
top-down (i.e. behavioural cloning approaches)
bottom-up (i.e. neural activity cloning approaches)
hybrid approaches
Top-down (or outside-in) approaches
Say that you:
measure behaviour in an animal or a set of animals with high accuracy
learn good generative models of it
embody it in a virtual body
You might eventually be able to create a virtual agent with all the same capabilities as animals of that species. This is, in theory, no different than generating handwriting, text, or images. Setting aside (dreaded) questions about philosophical zombies, I think this is quite feasible along several different axes.
Collecting behavioural data is easier than collecting neural data. Deeplabcut and related approaches have made behavioural tracking feasible with off-the-shelf tools. Virtual bodies are getting better thanks in large part to the video game industry (see video above for an example). There is abundant data of playing video games, e.g. Minecraft.
Furthermore, training an artificial neural network in silico on a behavioural task often leads to solutions like the brain’s [previous coverage on xcorr here, here and here; although see here for a counter-example]. Thus, this purely behaviourist approach might find representations which converge to the brain’s.
Aside: metrics
An important question is how to measure the capacity of agents that work on the principles of behavioural cloning. The naive approach of the whitepaper, as noted by the whitepaper itself, doesn’t work if the agents are chaotic; after a certain time horizon, prediction becomes impossible in principle. Varying Turing tests have been proposed to measure the capacity of agents:
Navigation Turing test: “predicts human judgments of human-likeness” in the context of a navigation task
Embodied Turing test: “challenges AI animal models to interact with the sensorimotor world at skill levels akin to their living counterparts”
Now, we could use next-token prediction in the style of GPTs for optimization, but we can’t use that for evaluation over long horizons. In addition, that metric, while useful for pretraining, is not aligned to the final desired outcome. Ultimately, we will need to choose what kinds of behaviours are considered equivalent, or what kinds of equivalence classes are defined by our chosen metric. This papers proposes to use distributional alignment rather than MSE or cross-entropy for long-horizon behavioural prediction.
Bottom-up (or inside-out) approaches to WBE
Mitelut also documents bottom-up approaches to whole-brain emulation. Here, rather than cloning the behaviour of an organism, one clones neural activity, i.e. the electrophysiological activity of neurons. Konrad Kording and colleagues are proposing to use causal manipulation of neural activity in C Elegans to fully reverse engineer a worm’s brain, thus sidestepping the issues translating the connectome to neural activity. But could you scale this to a mouse or a man?

Mitelut points out that, extrapolating from current trends (e.g. Stevenson and Kording 2011), we wouldn’t reach human whole-brain recording capacity until the 2060s, by which time I will be retired.

That conclusion rests on a few assumptions, which I think are debatable:
There will be no breakthrough technologies in brain recording that change the slope of the current curve. People are trying to change that, e.g. Sumner Norman has a new startup using ultrasound for whole-brain recording, Mary-Lou Jepson is pushing forward with OpenWater, my old group at Facebook demonstrated 32X increase in SNR in diffuse correlation spectroscopy, etc.
You need to record the whole brain to have any chance at WBE via this bottom-up approach. If you believe the random manifold theory of brain coding, a random sparse subset should be sufficient.
You can’t stitch together recordings from multiple organisms together to obtain one equivalent amortized organism. Recent results from Matt Perich, Juan Gallego and co. show that different individuals from the same species learn equivalent latent manifolds to solve motor tasks, which means alignment should be feasible in theory. This has motivated some significant advances in neural stitching from my colleagues and I, which I think could change the game.

I agree in principle, however, that purely bottom-up approaches are hard to get working without any anchoring to behaviour.
Hybrid approaches to WBE
That brings me to a third set of approaches, which attempt to stitch together observed behaviour and neural data. There hasn’t been a ton of work in this area, but I’m quite bullish on the whole concept.
We’ve seen a few areas where training a particular ANN architecture, with the right inductive biases, on the right combination of tasks, leads to a trained architecture that has an excellent one-to-one correspondence between simulated and real units. This has been shown in the retina by Niru Maheswaranathan et al. (2023), which I mentioned a few newsletters ago. This is also apparent in work from Lappalainen et al. (2023), which trained a network with the exact connectome of a fly, derived from EM, with task-driven learning, to obtain a pretty solid model of a fly’s optic flow detection system.

Challenges and opportunities
From watching a number of the talks in this series, WBE–lo-fi and hi-fi varieties–is more feasible than I had originally pegged my estimate. It certainly seems a lot closer than the 40-50-year timeline that I’ve seen quoted (reference; derived from surveys of AI researchers), especially when it comes to lower-fidelity approaches. Are we likely to bump into insurmountable obstacles along the way?
The original whitepaper estimated that in 2019, a human-sized population of integrate-and-fire neurons could be simulated by a supercomputer that costs a million dollars. Are we close to the count? If we stick to a 1 exaflop estimate for a whole human brain, we could achieve real-time simulation with 1000 H100s2. That would cost more than a million dollars (perhaps 30M$3), but it’s not an infinite amount of money either, nor is it out of reach of the best-funded academic institutions. As a point of reference, Harvard’s Kempner Institute announced it would acquire 384 H100s.
If compute is not a limitation, then what is? If we require a whole connectome, we’re talking billions of dollars at current costs to acquire that data (it cost ~100M$ to scan 1 mm3 of mouse cortex in the MiCRONS program). If we assume that the cortical algorithm is universal–that we can infer universal connection rules from measurements of partial connectomes–then we might not need a whole-brain connectome. Lo-fi approaches based on distilling behavioural and neural data are cheaper still. How much brain and behaviour data do we need for lo-fi approaches?
Another open question is about reducibility. What is the purpose of a WBE model at 1/10th the (spatial|temporal|behavioural|neural) resolution? 1/1000th? What about coverage: do we get anything by simulating, with very high accuracy, a small chunk of cortex?

We’ve learned from the story arc of Henry Markram–the leader of the Blue Brain project who promised to send a hologram of himself to a TED conference by 2019. We have to have to carefully manage expectations about the potential benefits of simulating a significant chunk of the brain. We have to go several levels deeper to identify the downstream users of these technologies and find capabilities which are likely to be unlocked at different levels of resolution of these technologies. If we shoot for the stars and miss, can we make it to the moon? While the endgame may be a form of AI, the intermediate applications are likely to be in human health.
If we can make clear the link between the fidelity of a simulation and corresponding capabilities which get unlocked, we’ll have a much clearer technology tree benefitting both AI and neuroscience. This is an exciting project for NeuroAI in the coming years.
Yes, that Bostrom. He’s problematic, to say the least. I haven’t been able to find a good replacement reference on the same topic.
This is a back-of-the-envelope calculation–it could be off by an order of magnitude on either side.
For mere mortals; for Nvidia, it might cost more on the order of 3M$.
I think there are two major concerns with the approach and goals as you have outlined them—even allowing for this to be a speculative and rather general take on the goals. As an ex-and-sometimes-still philosopher, I am comfortable with thought experiments. So let’s consider the goal in the context of science and potential value to humanity. There is also the option that we want to produce a First, let’s assume that you could produce a WBE. Let’s also assume that you could do it using a top down or bottom up (and therefore, by extension, by a hybrid) approach. Now the question is, what would be the necessary ancillary assumption needed for this to be a useful investment of time and resources, or of scientific or societal value. Let’s start with the bottom up approach as proposed by most of the current efforts. As you noted, there are a series of assumptions that need to be met for this to be both possible and useful as an endeavor. First, the emulation would need to match that of a (human, mouse, drosophila, c elegans) brain and behavior to a meaningful level. This is the concept of a reasonable tolerance or error. However, if the goals is to emulate (human, mouse, drosophila, c elegans) neural and behavioral activity, we need to be able to measure it all to make the comparison at all. This means, for a WBE project to be meaningful, we can discard for the near future human and mouse—but most likely the rest of the model organisms, as we will see in a moment. This is simply because the capacity to reasonably measure even a low-dimensional readout of the neural activity of the system is way, way beyond the capacity of any near-term foreseeable technology. And probably prohibitive by physics—because measuring systems alters them and in the case of a brain, the best measurements we use today literally damage the tissue and only capture an infinitesimal fraction of the neural activity. And it gets worse, because if the state of the system—the initial conditions—need to be measured accurately for the WBE to compared to the model, we likely need to at least capture some sub-neural states, as DNA methylation, current RNA and protein production we know effects neural activity—even before considering current hypotheses that suggest these are directly involved in neural computation. So, if we cannot measure the systems output to validate it within a tolerance nor measure its internal state, we fail to get off the ground before we even start or consider problems of the granularity of the emulation. Chaotic dynamics come from the model we use being exponentially divergent with respect to initial conditions, but our philosophical thought experiment could allow for a perfect capture of the initial conditions and the system dynamics. However, for this to be useful, the emulation would need to operate at on order realtime and within a compact system (i.e. the memory required would need to be on order what we can imagine in the near term for computing systems on earth). But simple back-of-the-envelope calculations suggest that if you take even a simple system and try to emulate it with an approximation approaching something that will be non-chaotic for timeframes and scales we care about, we are going to need far more capacity and the system would be run orders of magnitude slower than real time. So, it seems that conceptually, without respect to the specific (and thoroughly ludicrous IMHO) claims about using a single point sample of a connectome to produce an emulation that is useful using very low fidelity emulated (neural) units, we can see that the bottom up approach fails to make any sense for WBE. What about top down? Well, then we have a different problem. If we take the class of models that could reproduce the observed behavior of a system, sans any other assumptions or limitations, we know that class of models to be infinite. And we will gloss over the problems we already identified on the practicals of computability and measurement and simply focus on how would we select from the infinite class of models that exist that can produce the observed behavior? Well, we would need to use other criterion. Namely, approaches that restrict the computations, or memory, or the elements of the emulation, or some-such. So, then we are already in the hybrid domain. Now, interestingly, the hybrid domain is something that has existed for a while—it’s called computational neuroscience or cognitive psychology or similar, depending on your background. But there is a further problem if the hybrid approach’s goal is WBE. We humans use science to describe the world in compact forms, that average over aspects we don’t care about for specific questions—but that are accurate to within good tolerances for the questions we do care about. The goal of science is—in part—hermeneutical in that it helps us interpret what we observed in a common frame of reference that is publicly observable. Science is also about utility. We need the science to solve practical problems, inform us about new experiments, and generally provide frameworks for understanding the world that provide a common way for humans to interact with the world. Understanding and utility are interconnected. The hypothetical WBE is only useful if it is actually many orders of magnitude more compact than the actual system. It also needs to align to principles that help with using it to do things. So a useful WBE actually looks like what we do with traditional computational neuroscience—we try to understand and reduce the complexity of the system so that we can efficiently explore the space of neural activity or behaviors orders of magnitude faster than just observing the actual system. So, a useful WBE must be more efficient for understanding and use than just observing the actual human, mouse, etc. and must provide us insights into how to think about concepts of memory, intelligent behavior, etc. in ways that allow bridging between animals (and AI). So that brings me to the last possibility implied in the original and commentary—could a WBE be useful for developing and AGI? Well, if it met the criteria for being useful for neural (behavioral, biological) science it would presumably be for AI as well. But lets assume it fails the assumptions to make the thought experiment useful for ‘science’ and instead we could just use it to produce an AGI. At best, we would have all the above problems and in addition, an intelligence that we didn’t understand and would be massively expensive (memory, computation) in that it needs to reproduce all the behavior of our current benchmark for intelligence, humans. But if to get to AGI we need to first create a WBE of a human, then we will have produced an AGI that is just as good as a human, but without the interpretability or compactness that would allow us to ‘improve’ the AGI with respect to known human failings, etc. And it would only help with alignment to the extent that we could observe that it acted like a human in all observed contexts—we wouldn’t really know how it would act out-of-sample when used for things we might not want to use humans for—as that isn’t part of our WBE definition. So, all things considered, I’m not very optimistic that there is even a logically coherent definition of a WBE that isn’t—in reality—just doing good science. But that doesn’t get you the money or hype that Markram and others have used to waste vast resources and it has created efforts to do things that make no sense. For example, what we need—precisely for reasons you cite—is not a larger, more precise connectome, but we need a really good course connectome that is statistical in nature, allowing us to have the variance we need to understand how that variance relates to learning, individual differences, etc. But instead we are wasting vast resources making bigger ‘single-shot’ connectomes. Now I am not naive enough to think that this won’t provide valuable insights. The same applies to all the circuit cracking that is the norm in systems neuroscience today. But it won’t get us closer to WBE nor to understanding the brain or intelligence. It will just be more constraints and more data for us to try to use in that process. And given how power our best models that can connect behavior and course neural activity to computations and predicting future learning and behavior, we should probably focus our efforts on meso-scale (lo-fi, if that’s what they really mean) computational models that use or expose reliable principles and course-grained descriptions of neural activity and behavior. These, conveniently, exist and are already in use in both the neuroscience and AI communities—reinforcement learning (broadly defined) is a good example.
One hitch in the WBE approach: the WBE is useless without WFE or Whole Family Emulation. If you take a human infant and deny it the affection of a mother or movement or exploration, it will not develop into a normal human being. The same is true for WBE. WBE takes care of nature but a lot of what we are is nurture.
For more on nature and nurture, see https://tomrearick.substack.com/p/invention-enables-genetic-adaptations