
Foundation models for neuroscience
Opportunities and pitfalls of large-scale models

I’m giving a talk for the NIH Neuroethics Working Group (NEWG) on foundation models for neuroscience on Aug 21st1. The audience is neuroscientists, philosophers and ethicists involved in the burgeoning field of neuroethics. “Foundation models for neuroscience” is a broad enough topic that it can be hard to talk about all its implications–both opportunities and ethical pitfalls–in a precise way. I’ll focus on a technical overview of the field, at a sufficiently high level of abstraction that folks outside of technical AI work will be able to follow, yet concrete enough that we can talk about specific risks and opportunities. It’s a tough line to skirt, so I’ve decided to write some of my remarks here and collect early feedback.
This post will start less technical than usual, but it will ramp up in later sections. I would love to hear your thoughts in the comments, via email or on X. Let’s go!
What’s a foundation model, anyway?
A foundation model is an AI model that serves as a foundation–a basis–for multiple downstream use cases. Some defining characteristics of a foundation model include:
It’s pre-trained in a self-supervised or unsupervised way to learn the distribution of the data it attempts to model
It is then finetuned to allow it to perform a downstream task
It is trained on large-scale data
It leverages large-scale compute
It contains a large number of parameters
It leverages generic architectures with weak inductive biases–mostly transformers, but also convolutional neural networks and state-space models–that are well adapted to training at scale in highly performant clusters
Its performance on its pre-training task is predictable as a function of data size, compute, and model size–scaling laws
They may display emergent properties not immediately visible in the pre-training task
Large language models, in particular, display emergent properties such as reasoning and in-context learning, despite being pre-trained on next-token prediction
A foundation model is composable; its trained weights, the result of large-scale training, can be used to initialize larger systems, which may include other foundation models or conventional machine learning models as subcomponents.
This setup in terms of stages of pre-training and several stages of fine-tuning was popularized by ULMFit, which proposed this pipeline for natural language processing:

Foundation models include:
Large language models, LLMs, such as GPT-4, Gemini, Claude or Llama
Vision models such as ViT-22B or Segment Anything Model (SAM-2)
Generative vision models such as Dall-E, Stable Diffusion and MidJourney
Speech-to-text models such as Whisper or DeepSpeech
Generative audio models such as Udio or Suno
Vision-language models (VLMs) such as CLIP and SLIP
Vision-action models such as PaLM-SayCan
DNA, RNA and protein foundation models such as Evo, AlphaFold, RoseTTAFold and ESM-3
Models have different levels of openness, including:
Closed source, usable via a web of chat interface
Perhaps the model is available via an API, which facilitates automation
Open weights, which means that the model and its checkpoints are available, but training scripts and data might not be available
Open source, which means that everything needed to reproduce a training run is available, including training scripts and data (although, in practice, one might not have the resources to do so)
Conventionally, the most capable foundation models have been closed-source models, although the gap has closed recently. Open weights and open source models are most relevant to composability: they can be easily integrated into a larger model and adapted–fine-tuned–for downstream use cases, in particular for science.
A specific example: Llama
To make things concrete, let’s look at a specific model, Llama 3.1-405B-Chat. This is an open weights large language model (LLM), tuned for chat, trained and released by Meta in July 2024. It is, at the time of writing, one of the most performant open weights large language models out there. Let’s see how it stacks up to the foundation model checklist:
It’s pre-trained to perform next-token prediction on text from the internet: predicting what comes next in a sentence
It’s fine-tuned to be useful as a chat model in several rounds, using a combination of supervised finetuning (SFT) and direct preference optimization (DPO)
It’s trained on 15.6 trillion tokens, a significant subset of the internet. Writing this text would take a single human tens of thousands of years.
It’s trained on up to 16,000 H100 GPUs for a total of 39.3M GPU hours, which on the open market would cost about 80M$.
This is only part of the total cost of the project. At 500 listed contributors, salaries likely add up to a comparable amount to the compute cost.
It contains 405 billion parameters, which is far larger than what will fit in a single GPU’s RAM.
It’s based on a transformer that is largely unchanged from previous generations of the same model
The hyperparameters of the model–the number of training tokens and weights–were tuned to maximize performance for a fixed training budget by training small-scale models, computing scaling laws and extrapolating.

Scaling laws for smaller variants of Llama, used for hyperparameter tuning It displays strong results on downstream tasks including question answering, code generation, and multilingual reasoning

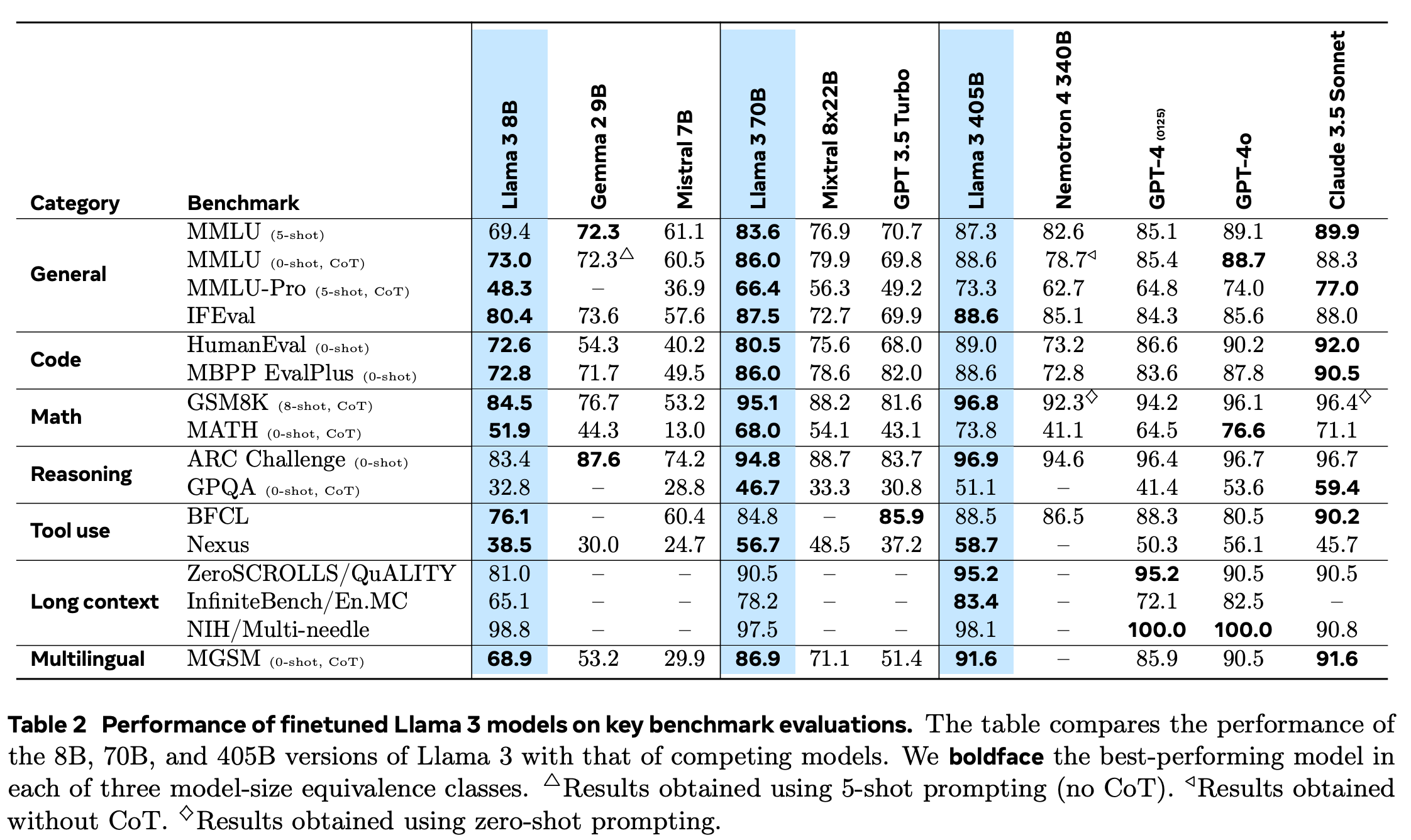
Some of its variants include adapters to ingest images, video and audio. The image encoder is a variant of CLIP. It is pre-trained on 2.5 billion pairs of images and corresponding text before being integrated as a component of Llama and fine-tuned end-to-end.
Already, we see several common characteristics of foundation models compared to more conventional, smaller-scale deep learning models that will be relevant to ethical discussions:
They require large-scale engineering efforts to train from scratch, often far larger than what is available in a single academic lab
Academic actors may, however, be in a good position to perform finetuning or evaluations of models which have been released as open weights
The National Deep Inference Fabric, spearheaded by David Bau, is experimenting with offering free compute to academics trying to figure out what’s going on inside of large-scale models.
Pre-training data is critical for the operation of these models. However, the sheer scale of the pre-training data makes inspecting the raw data challenging.
There have been high-profile instances where very problematic data were part of training sets, including CSAM in the case of the LAION-5B image set.
Evaluation of model capabilities and limitations is non-trivial, as one-dimensional downstream metrics don’t capture the full breadth of what is in the models
Because of their sheer size, it’s challenging to understand why foundation models work and to attribute their predictions to specific architectural components or data
There is an entire subfield of interpretability, including mechanistic interpretability and representation engineering approaches, that seeks to find mechanistic explanations for how the models work and to move them toward more helpful, less harmful behaviour. It’s become fashionable to release interpretable decompositions of these models to try and figure out what’s going on inside (e.g. the recent Gemma Scope from Google Deepmind).
Composability, the wide availability of engineering tools and plentiful capital means that the field evolves very rapidly, and it can be hard to keep up
Blogs, newsletters and podcasts such as AINews (technical) or One Useful Thing (by UPenn prof Ethan Mollick, but aimed at a generalist audience) can help cut out the noise compared to the firehose of arXiv and conference papers.
What’s a foundation model for neuroscience?
Neuroscience is no stranger to the excitement around foundation models, and there have been several papers moving in that direction. I’m not going to make a strict distinction between foundation models and conventional machine learning models in neuroscience for this discussion but rather will focus on models which check off a large subset of the foundation model checklist.
We can broadly categorize these models in terms of which specific aspect of the relationship between an organism, its brain activity and its environment it attempts to model. Consider this (slightly Fristonian) diagram:
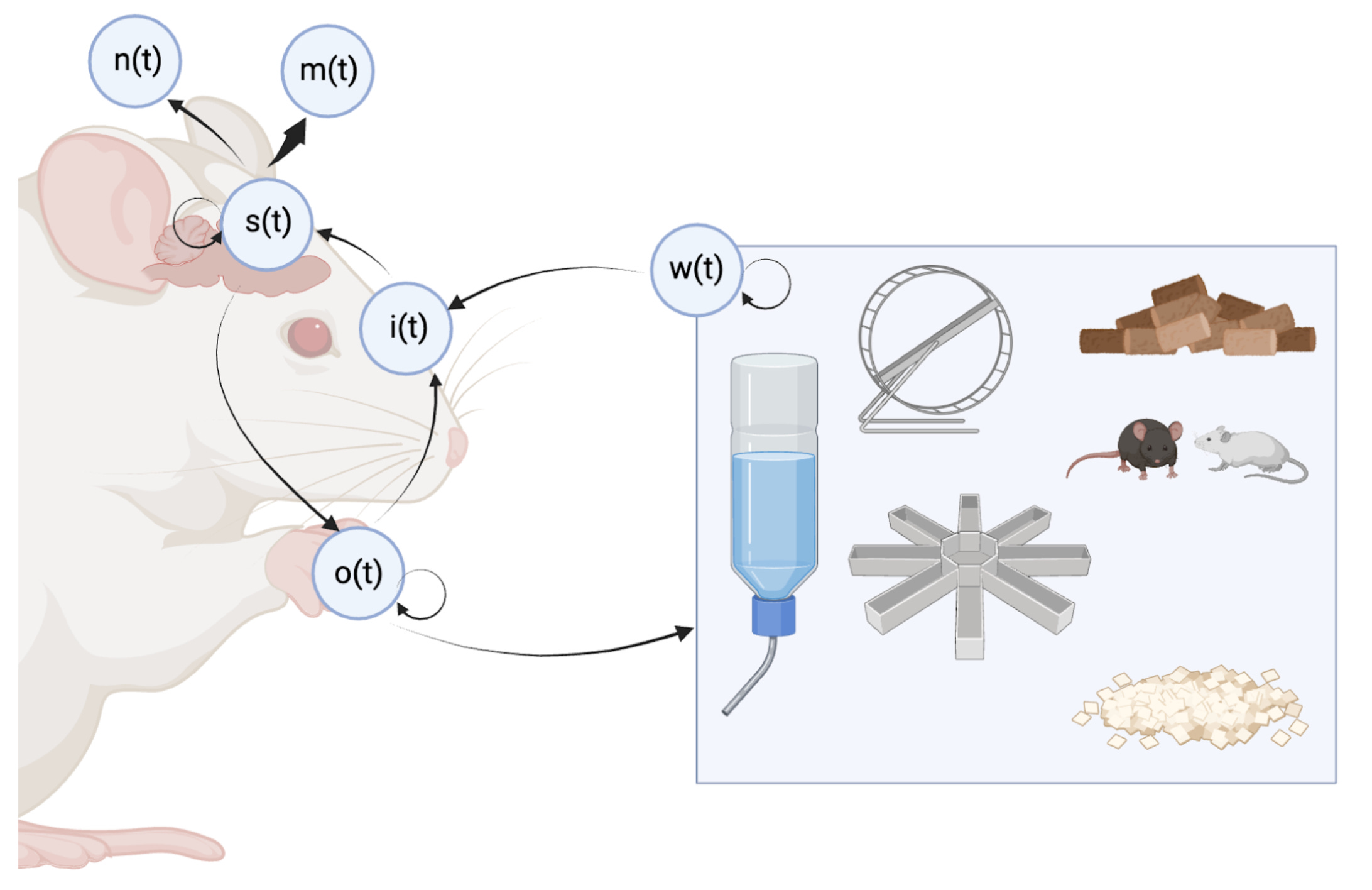
The world determines the sensory inputs of the subject; the sensory input exogenously drives ongoing neural activity; the neural activity and the mechanics of the body determine its position; and the body affects both the world and the sensory input of the animal. All the while, we can take measurements of brain activity, either invasively or non-invasively.
Many models perform a kind of graph surgery focusing on one or more nodes of this loopy graph, depending on the end use case2. Keeping in mind that these categories are fluid–e.g. an encoding model can easily be turned into a decoding model via Bayes’ theorem–it is nevertheless helpful to distinguish between these scenarios:
Encoding models :: sensation → measurements.
Data-driven models focus on learning the mapping between sensation to measurement from scratch. When trained at scale on single neuron data, these models are sometimes referred to as digital twins, since they can be used instead of the real brain for virtual experiments (e.g. work from Alex Ecker, Andreas Tolias and many others [1], [2], [3]). This is most relevant where invasive data is plentiful, and inputs can be easily controlled, e.g. in vision.
Goal-driven or task-driven models focus on using AI models–often foundation models–trained on specific tasks, and mapping them to or comparing them to the brain. This has been popular not only in the context of vision but also in audition and language (e.g. Dan Yamins, Niko Kriegeskorte, Alex Huth, Ev Fedoronko’s work). Generally, the starting point has been models trained at large scale on AI tasks for other purposes, for example, image recognition. On occasion, models are trained from scratch, though they generally fall short of qualifying as foundation models (e.g. Mehrer et al 2021, Mineault et al 2021).
Modelling the distribution of measurements :: measurements
Models can be trained to model the distribution of functional measurements, e.g. spikes trains, calcium imaging, EEG, MEG, fMRI, etc. Models such as LFADS are trained to compress neural data into smaller dimensional latents, which helps denoise and interpret neural data3. Masking and next-token prediction can also be used to find good latent representations without compression. Such models can be used for co-smoothing (e.g. predicting what a held-out neuron’s activity should be), or, in the same style as generative pre-trained transformers (GPTs) for text, for autoregressive generation of future neural activity.
Measurements can extend to complex structural data, such as transcriptomes, connectomes or imaging data.
Decoding models :: measurements → sensation | behavior.
Decoding models have long been used in the context of brain-computer interfaces, to infer brain states, or to decode images from the brain. The advent of powerful models which find good latent representations of brain measurements has made these models far more powerful. When these models are applied to the decoding of structured sensory modalities (e.g. vision or speech), they can paired with powerful generative AI foundation models, leveraging their modularity. Striking examples have been shown, for example, of decoding seen images from fMRI, or decoding attempted speech from a locked-in patient in ECoG.
Models of behaviour :: behaviour
Models such as DeepCutLab–based on a foundation vision model, and fine-tuned to track specific animals–have become an integral component of investigations into neuroethology. Extensions to multi-animal tracking, as well as models which can work in the wild on humans, have extended the range of behaviours which can be tracked, quantified and compared.
Many excellent reviews have covered some of these topics:
Doerig et al. (2022): An overview of task-driven neural networks and the overall field of neuroconnectionism
Wang and Chen (2024): An overview focused on generative decoding models based on foundation models
Monosov et al. (2024): An overview of ethological approaches to computational psychiatry
Here, I’ll focus on the problem of modelling the distribution of measurements, which has only recently become possible at scale, with promising results. I have not been able to track down a recent review of these models, but I do keep a running table of the SOTA here (may be outdated by a few months).
An illustrative example: Towards a “universal translator” for neural dynamics
A paper released by Yizi Zhang and my former colleagues at Mila and Georgia Tech a few weeks ago illustrates some of the key technical components involved in learning the distribution of measurements–here, the distribution of spikes from electrophysiology measurements in mice, from the International Brain Lab (IBL) dataset. The IBL dataset contains large-scale Neuropixels recordings from multiple brain areas–thalamus, hippocampus, and visual cortex–while mice perform a decision-making task. This is a very rich dataset containing hundreds of hours of recordings. The authors here focused on a subset of the IBL dataset containing multiple recordings from the same areas, totalling 39 mice and 26,736 neurons.
The authors propose a pipeline to infer masked neural activity based on unmasked activity. Of note, to learn different useful downstream tasks–inferring the response of an unrecorded neuron, or region, or to predict neural activity in the future–the authors propose to train on multiple pretext tasks simultaneously (Tasks 1-4 above).

It’s worth it to stop for a second and ponder the nature of the modelling task to be performed. "Learning the dynamics of neural data” is a task that’s traditionally been tackled with unsupervised learning. For example, the now classic LFADS model uses a variational auto-encoder to learn an RNN which models the dynamics of neurons at the single session level. Unsupervised learning of that sort can be very efficient, but it does have some disadvantages: powerful generators can ignore learned latents, samples from the model can be over-smoothed, and tracking the progress of the model throughout training can be complicated (see e.g. the work on VQ-VAE to learn more about some of these issues and can be mitigated).
By contrast, masked autoencoding turns an unsupervised problem into a supervised learning problem, which is straightforward to train and scale. The model which infers one part of the input from another part of the same input can be pretty much anything one desires–a CNN, an RNN, a transformer, etc. The Universal Translator uses a version of the Neural Data Transformer–NDT– a straightforward scheme proposed by Ye and Pandarinath (2022). Specifically, it uses a variant of the NDT architecture which can handle multiple sessions–namely, NDT-1-stitch.
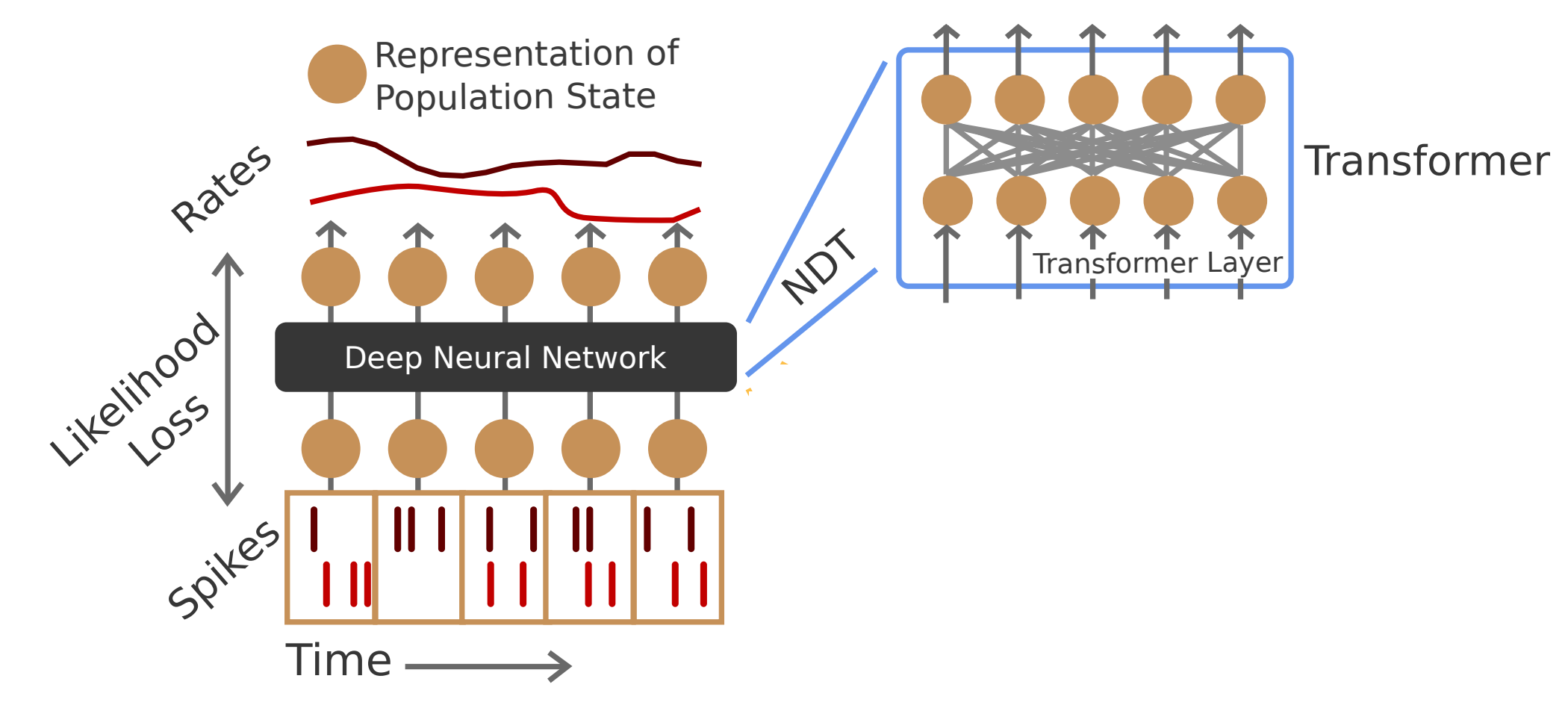
At the heart of transformer models of neural activity is a patching scheme: a method to transform neural activity into a set of discrete tokens which can be operated on by transformer layers. NDT-1 uses a simple patching scheme, where one time bin corresponds to one token4. First, neural activity is temporally binned; the original NDT paper uses 10 ms resolution, while the Universal Translator paper uses 20 ms. It’s then projected using a session-specific embedding matrix onto a fixed dimensional representation. Thus, a trial of length 2s gets transformed to 100 or 200 tokens. Standard transformer layers perform all-to-all attention to iteratively reformat this data. At the final layer, the tokens are unembedded to be used for the pretext task, prediction of masked neural activity. The Poisson loss is used to measure the mismatch between the predictions and the masked data.
Session-specific embedding matrices allow different datasets with different numbers of neurons to be handled by the same, fixed-size model. They also allow the model to implicitly align neurons onto the same latent space, “stitching” recordings together. Aligning different neural recordings together is a key technical challenge in these models, because it’s very unlikely that we ever measure the exact same neurons and voxels in different subjects.
The learned model can be used in several different ways:
It can be used as is to perform the same tasks it was trained on: predicting neural activity from one set of neurons to another, one set of areas to another or from the past to the future.
The learned model can be used to perform different tasks than the one it was trained on. One might freeze the learned model and put a logistic regression on top of the latent activity of the model to perform some downstream decoding task. Alternatively, one might put a (linear) decoder on top of the model and finetune the entire model end-to-end.
Here’s the model’s performance on the two sets of tasks. On the left four plots, we see the performance of the model on the same masking tasks the model was trained on. On the right two plots, the model is used to predict the mouse’s choice on an individual trial and the whisker motion energy during that trial. A baseline using less sophisticated masking is shown at the bottom.

These plots showcase typical results from a foundation model in neuroscience:
The model gets better as it is trained on larger and larger amounts of data (scaling laws)
The model’s performance is not restricted to the tasks it was originally trained on: it can be fruitfully finetuned for downstream tasks which leverage the latent representation learned by the model.
Or, as the authors state, “The performance of our approach continuously scales with more training sessions, indicating its potential as a “universal translator” of neural dynamics at single-cell, single-spike resolution.”
More is different
In the past, much of neuroscience has been concerned with the analysis of small-scale data, under controlled conditions, in a hypothesis-driven manner. Sophisticated large-scale recording technologies, including Neuropixels, together with archives to store large-scale datasets, many funded by the NIH–DandiHub, OpenNeuro, DABI, etc.–have led to an explosion in the size and breadth of publicly available datasets. Realizing the value of these extant datasets requires sophisticated tooling, engineering and methods: stitching together heterogeneous datasets often not designed with foundation models in mind.
I’ve had several discussions with hypothesis-driven-minded scientists who deride these efforts as “mere engineering” at best, or as “data dredging” at worst. I’ve had an equal number of discussions with professors who are worried about being left behind with the spread of AI methods which are inaccessible to most cash-strapped labs, a view reflected eloquently in a recent wonderfully titled editorial: “Choose Your Weapon: Survival Strategies for Depressed AI Academics”.
An optimistic viewpoint is that neuroscience is bottlenecked by a lack of tools, and foundation models distilling large-scale datasets are one such set of tools that might be useful for neuroscience. One of David Hubel’s core contributions to science, predating and enabling his Nobel-prize-winning studies of the visual cortex, was the invention of the tungsten electrode (Hubel, 1957). Tools tend to get commoditized; large language models are both far more powerful than predecessor natural language processing models, and far more accessible to the general public.
Here I show, in a rapid-fire sequence, some of the promise of recent efforts in foundation models for neuroscience, keeping in mind that the promise has yet to be fully realized. In particular, I want to make the case that more is different; that bigger models trained on larger scale data in neuroscience can display qualitatively different behaviour than smaller models.
Decoding sentences from EEG
Sato et al. propose to decode spoken sentences from EEG. Nothing unusual about this setup, except that they do so in a single subject from whom they recorded 175 hours of data.
The subject read sentences from a corpus displayed on a computer screen. They shaved the head of the subject (with dozens of sessions, washing gel out of hair becomes a bottleneck!). They trained a decoder composed of several pre-trained off-the-shelf models bundled together and fine-tuned end-to-end. They were able to reach 48% top-1 accuracy in a difficult 512-sentence classification task.
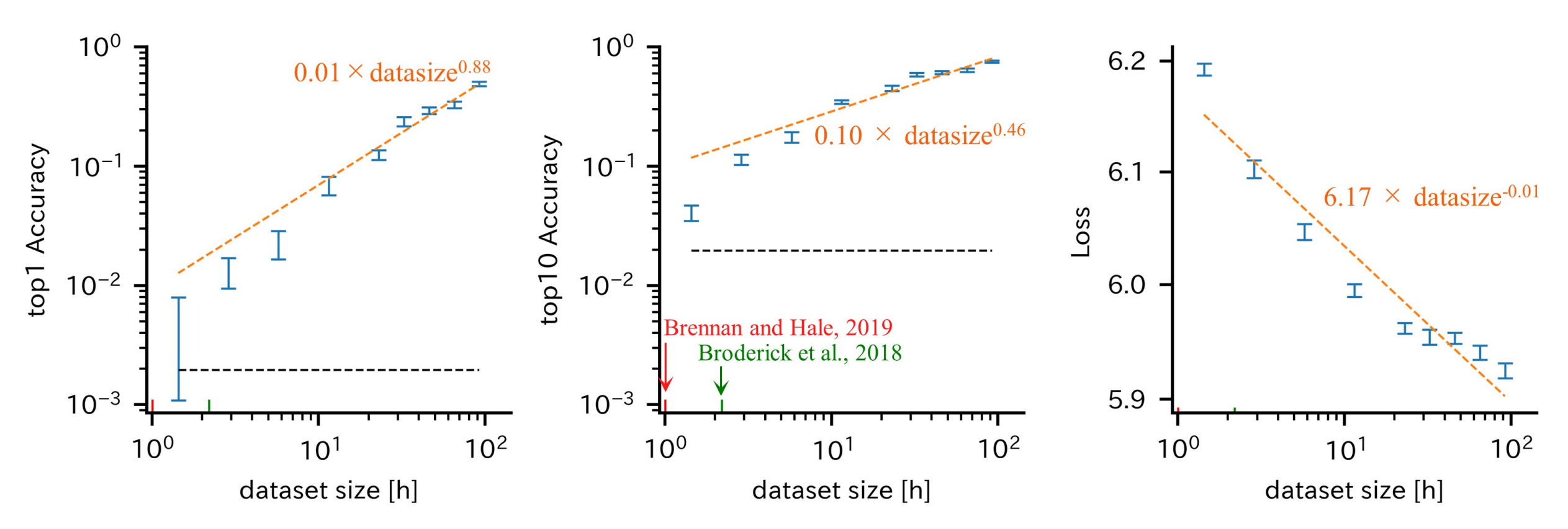
This is far higher than most people would expect from EEG, which has a reputation as being too noisy to be useful. To be clear, it’s not yet practical–who wants to calibrate an EEG headset for many months?–but it does show that decoding useful data from non-invasive signals might be feasible, especially if the representation generalizes across subjects.
Decoding gestures from EMG
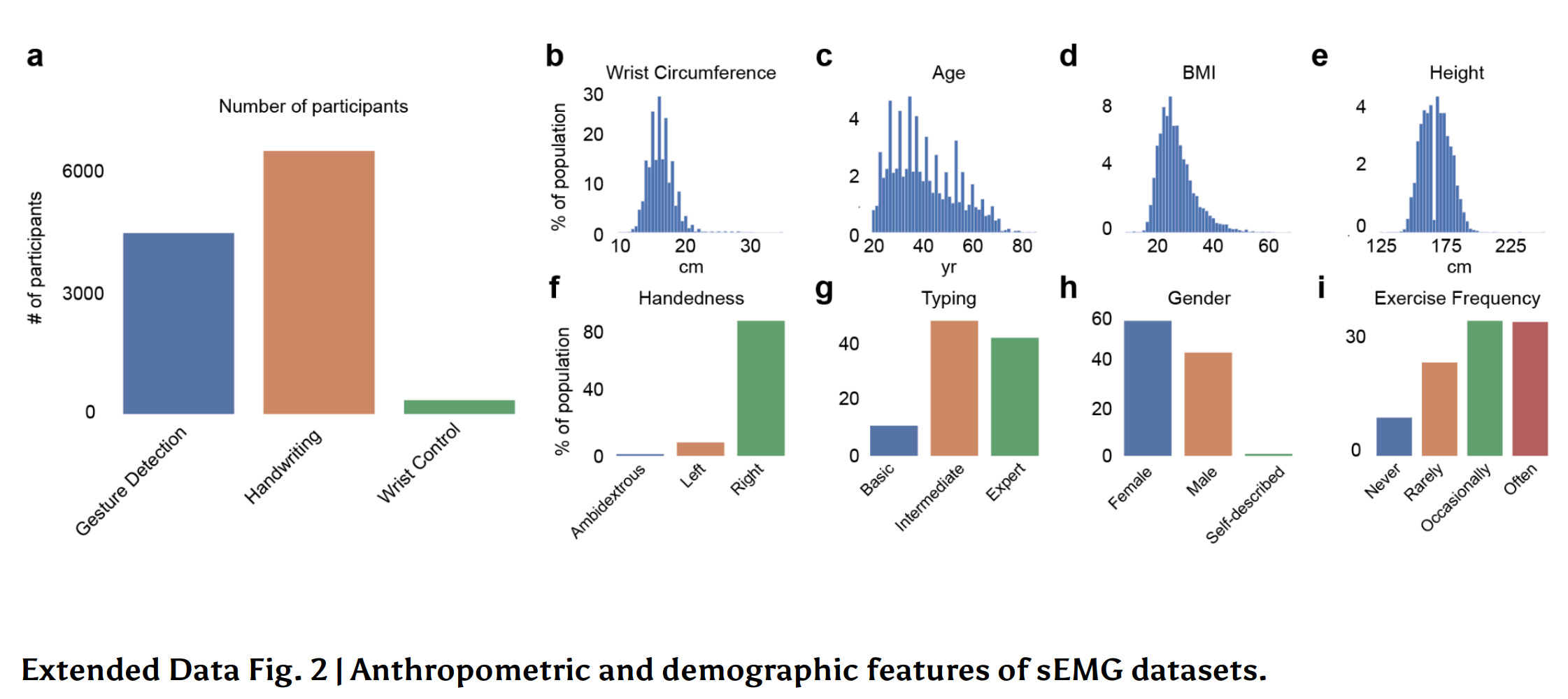
On the other end of the spectrum, Meta Reality Labs (my former employer many moons ago) has released a paper showing their ability to create good generic decoders of wrist-worn EMG by training on lots of subjects. Notably, each subject was recorded for a reasonable amount of time (a little more than an hour).

Notice the x-axis in these plots: the number of training participants is in the thousands. While this is clearly outside of the purview of a single academic lab, forecasting performance from a smaller number of participants via extrapolation of scaling laws might be feasible (see, e.g. Ruan et al. 2024).
Decoding images from the visual cortex
Several recent papers propose combining learning good latent representations of fMRI activity and powerful diffusion models to decode images from brains, which I covered previously on xcorr.

MindEye 2 showcases that it’s possible to reconstruct images from the visual cortex with as little as one hour of fine-tuning data from that specific subject.
")
This model makes use of all the tricks we’ve discussed previously–powerful pre-trained models with specialized bridges that are fine-tuned on large-scale data to enable generalization across subjects. The results are visually striking–although one has to be careful not to over-extrapolate from the visual results how well the model does.
Predicting neuroscience results from text
The previous papers make it clear that powerful brain decoders can be built by learning the latent structure of neural data through supervised and unsupervised learning. Foundation models can stitch together large-scale information in ways which exceed the information-processing capabilities of a single human.
Analogously, large language models can integrate information from large-scale data and identify subtle patterns which are difficult to find in single texts. An impressive recent demonstration is Luo et al. (2024), “Large language models surpass human experts in predicting neuroscience results”. They measure the ability of LLMs to correctly identify real neuroscience abstracts from counterfactual abstracts.

They assembled a dataset of abstracts published in 2023 in the Journal of Neuroscience and created synthetic versions of the same abstracts with the valence of results inverted. E.g. replacing suppresses with enhances, reduces with increases, etc. They then measured the likelihood of the real and fake abstracts according to pre-trained LLMs, directly using the perplexity measure that these models use to predict the next token. They found that LLMs could indeed identify the correct abstracts more than 80% of the time, despite not having been trained on these abstracts5, and that this was far higher than human experts (neuroscience PhD trainees and profs without access to a search engine). Base models performed better than chat models, probably related to chat fine-tuning hurting the calibration of these models; and larger models performed better. Of note, the output of the models was not a simple yes/no answer, but rather a continuous variable (perplexity over the abstract, in units of nats) whose absolute value expresses the certainty of the model and correlates with human judgement.
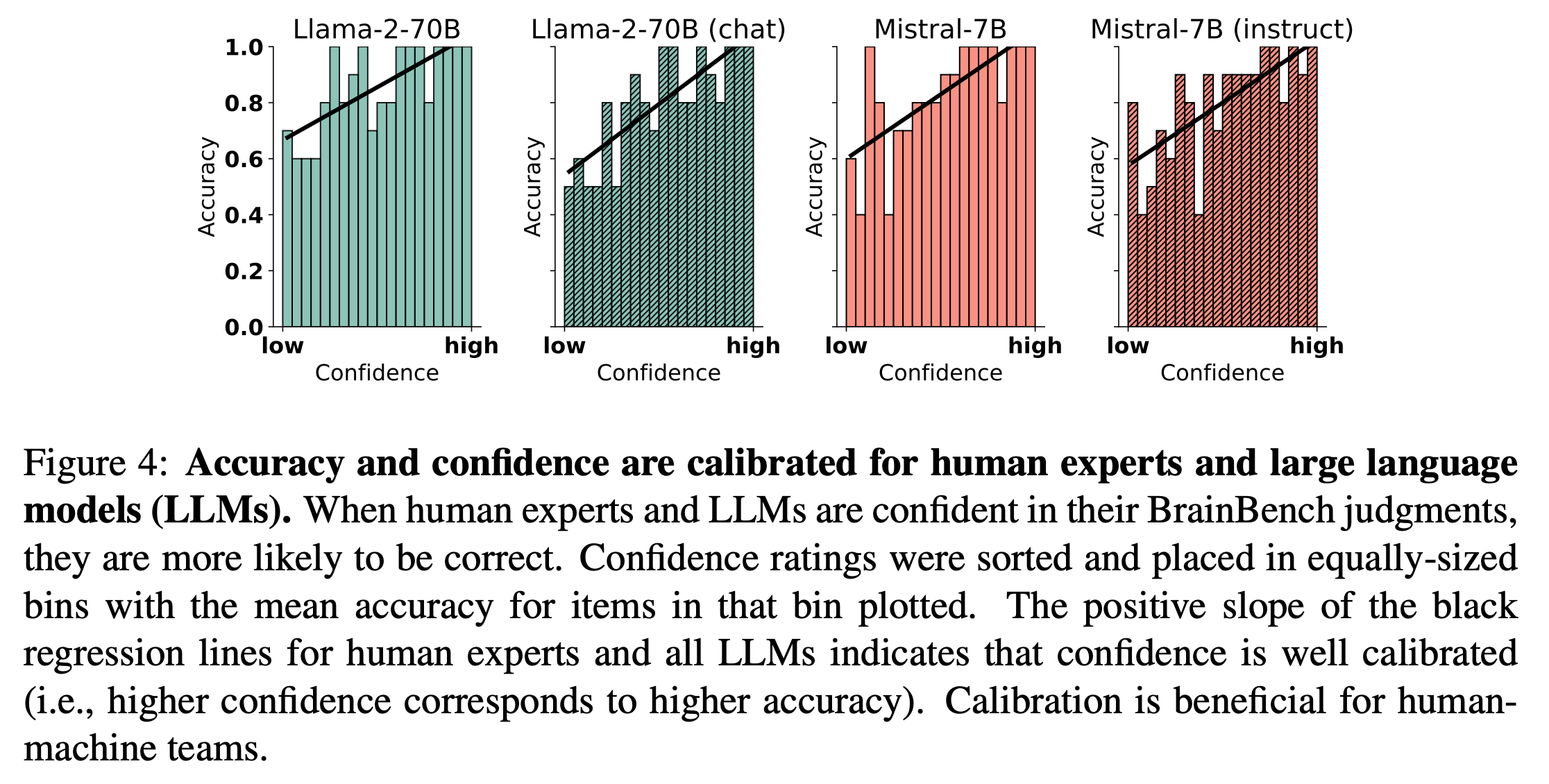
The resulting model could potentially be used in several use cases, including identifying controversial hypotheses that should be investigated or, conversely, identifying latent hypotheses which are likely to have already been confirmed in the literature. This paper is one example of a recent trend, LLMs for neuroscience, which was recently covered in a review from Danilo Bzdok and colleagues.
It’s not that easy
You might come away from this tour with the impression that one can throw a lot of data and compute into a high-capacity model and that’s the end of it. Of course, it’s quite a bit more subtle than that.

Foundation models are still susceptible to shortcut learning, where decisions are made based on accidental and brittle correlations. We can easily illustrate this with a ResNet-50 trained on ImageNet. Characteristic features of the category tench, a freshwater Eurasian fish, include human fingers, faces, and camouflage clothes. Here, the shortcut learnt relates to sports fishing: consequently, identification of the animal in its natural habitat is impaired. Similarly, the EEG speech decoding study almost certainly leveraged EMG artifacts from the jaw muscles generated during overt speech to boost performance, as opposed to decoding only neural activity, although they did bound the extent to which this happens using a synthetic data analysis.
“Universal decoders” can fail if they’re not trained on representative samples of the population; the Meta team did a good job of recruiting a demographically representative population, but suffice it to say this required a lot of resources that are often inaccessible to single academic labs.
Powerful generative decoders can fool human observers into thinking that they perform better than they actually do. When we judge the quality of a decoder, we might rely on superficial features, like the aesthetic qualities of the generated images or speech, as opposed to how well-grounded the generated sample is to the neural data. Shirakawa et al. (2024) report that this type of generative decoding model tends to overfit to the distribution of the inputs, such that they fail to generalize out-of-distribution.
Large-scale models are only as good as the data that’s fed into them: garbage in, garbage out. LLMs can fall for imitative falsehoods, repeatedly debunked falsehoods in the raw dataset, unless they’re carefully fine-tuned away. These imitative falsehoods, which can be detected using benchmarks such as TruthfulQA, can range from the benign–e.g. the idea that cracking one’s knuckles causes arthritis–to the harmful–election denial and mischaracterizations of the efficacy of vaccines. In the same way that wrong or incomplete neuroscientific hypotheses can have a long shelf life through repetition, for example the chemical imbalance theory of depression, large-language models can fall for oft-repeated but scientifically dubious “facts”.
Finally, large-scale training is not a panacea for all problems. The accuracy on downstream tasks depends not just on the size of the training sets, but also on the accuracy of the labels, the dimensionality of the signal, and the signal-to-noise ratio. Schulz et al. (2022), for example, extrapolated from current datasets in brain-imaging-based phenotyping to estimate how well these methods would work when tested on a million subjects.

The results were sobering. Even at a data scale of a million subjects, which could easily cost a billion dollars to acquire, MRI-based classification accuracy was projected to reach roughly 0.6 for depressed vs. not-depressed, barely above chance. Scaling laws can be cruel, with performance improving only log-linearly with dataset size.
Foundation models for neuroscience: opportunities and pitfalls
We can view foundation models in neuroscience as a logical extension of an ongoing trend: training larger models on ever larger datasets. A basic mental model for the current trends is that it’s simply more of the same: more data, more parameters, and higher accuracy. Previous assessments of the opportunities of the machine learning models in neuroscience and their pitfalls, in this view, are simply amplified, both positives and negatives.
I’ve taken a slightly different view here, which is that bigger models can be qualitatively different:
Foundation models are composable, which enables more rapid progress than training from scratch for each task
Foundation models can be used for multiple downstream tasks–even unanticipated tasks–via a simple process of fine-tuning. It moves us from a world of bespoke models to a library model, e.g. LEGO bricks.
Although training from scratch is too resource-intensive for many academic labs, downstream uses don’t require nearly as much compute
Foundation models can take advantage of unlabelled data, which is far more plentiful than labelled data. Hundreds of thousands of hours of data are stored in public archives such as DANDI, OpenNeuro and DABI.
Although metadata can be of varying quality in these datasets, LLMs can be used to assist in metadata extraction and filtering.
Foundation models have been proposed for data formats which have resisted conventional large-scale machine learning, e.g. graph data, spikes, transcriptomics, etc.
Foundation models are somewhat of a misnomer–the models themselves, transformers et al.–don’t matter nearly as much as the data that’s used to train and fine-tune the models. This data-centric view of AI is a mindset and tooling shift from the previously prominent model-centric view.
I’m excited about the applications of foundation models in both discovery and applied neuroscience. Powerful, off-the-shelf and accessible tools have the potential to accelerate discovery in neuroscience, by making the value in existing datasets visible. They also have the potential to accelerate applications, for example in the context of brain-computer interfaces, making use of rich data to make invasive interfaces more data efficient and noninvasive interfaces more accurate.
Foundation models, like their more specialized single-use machine learning predecessors, when used in sensitive human health-related applications, have the potential to amplify societal biases, deplete autonomy and agency, and raise important privacy concerns. These concerns, which also exist for AI systems at large, have been the subject of several excellent books (e.g. The Alignment Problem). It’s likely that existing ethical frameworks for machine learning in neuroscience–e.g. here and here–already anticipate and can accommodate many of the consequences of foundation models.
The question that I will try to address during the NEWG meeting is whether there are unique risks which are posed by foundation models over and above conventional models. I’m a technical person, not a bioethicist, so I tend to think of risks in technical rather than societal terms, caveat lector. There are three unique categories of risks that I foresee.
The first risk comes from the inscrutability of models trained at a large scale. It takes resources and diligent work to fully characterize the model’s biases across a wide range of downstream use cases; to suss out instances of shortcut learning; and to visualize all the data used in training. It’s largely thankless work that’s poorly incentivized in conventional academic environments–that is, it maps poorly to papers. It’s also not necessarily something that scientists are trained to do.
This could be addressed, however, by novel funding mechanisms specific to tooling, by the hiring of data scientists and engineering, as well as by building training courses on the uses and misuses of large-scale models. Because foundation models are so data-centric, projects which are organized around the creation of high-quality datasets and tooling are highly relevant. We’re seeing a Cambrian explosion of innovative non-profit focused research organizations (FROs) and large-scale academic projects that scale neuroscience data collection and foundation models for science, like e11bio, Forest Neurotech, FutureHouse, and the Enigma project.
The second, related risk stems from the paradox of automation: as more capable machine learning systems get integrated into decision-making, we trust them more, and become less capable of correcting their mistakes. One (rather naive) example is in automated seizure detection: as machine learning-aided detection becomes broadly more useful, less time is spent on examining the raw data, fewer practitioners are competent in reading the raw data, and mistakes take longer to be noticed and corrected. Human-AI teams tend to cluster into either the human doing all the heavy lifting (when the AI system works poorly) or the AI doing all the work (when the AI system is effective).
The third is around equitable data access. Foundation models are both data hungry and valuable. The prospect of transforming sensitive neural data, collected through neurotechnology, into intellectual property should give one pause. This raises critical questions about data ownership, privacy, and the potential for exploitation.
I do think that despite these challenges, these risks can be mitigated with the right regulatory and funding environments. The potential of foundation models in neuroscience to accelerate the discovery to clinical translation pipeline is truly exciting. These models offer unprecedented opportunities to analyze complex neural data at scale, potentially uncovering patterns and relationships that have eluded traditional methods.
I’m speaking after NIH Brain Initiative director John Ngai and MacArthur “genius award” recipient Doris Tsao, no pressure.
Note also that models aiming to cover all of these nodes simultaneously are in line with recent proposals to create embodied simulations of animals–e.g. the embodied Turing test proposed by Zador et al (2023).
Finding good representations of neural data is an easier goal than finding the true underlying causal graph generating the data, which in general requires causal interventions. I’ve discussed this here.
The models were trained on internet data with a temporal cutoff before the publication of the J Neuroscience papers, which neatly prevents contamination.
Really interesting post. One thing I am worried about is that these give us the illusion of progress in neuroscience, but don't lead us to a mechanistic understanding of the brain. I'll admit it is a personal professional bias of mine. I guess I am one of those hypothesis-driven-minded scientists. In a way I wonder if the criticisms that were leveraged years ago against the BBP would not work here too.
I didn’t aim to be an artist because of the accuracy. But it surely helps to see well diferences in colours.