


ML tools for scientists
There's thousands of AI tools; which should you pay attention to?

I gave a talk in October at a fantastic workshop organized by Greg Field and EJ Chichilnisky at Stanford on exploring/exploiting AI tools for working scientists. The idea was to have several people from industry and academia discuss tools and use cases for ML tools in (neuro)science–LLMs, image generators, and whatnot–and to try them out in person. It was a lively discussion and it was interesting to see the mix of enthusiasm and skepticism. I volunteered to do a write-up and promptly got distracted by other things. Here, I’ll give a walkthrough of some of the most salient points that were discussed and link to tools and resources. I’ll also post some common pain points and gotchas as you navigate these tools.
There’s a lot of negative discourse around ML tools, including from scientists (some examples). It’s easy to use these tools in agency-depleting ways: doing superficial readings of texts and summarization rather than deeply engaging in papers; have code LLMs write bad code that cause a giant pile of tech debt; and delegating the fun, rewarding parts of your work to an unthinking machine. But they can also be used in agency-enhancing ways. My goal is to give you a path toward the latter.
Meta: choosing the right ML tool
Someone on X1 mentioned that they couldn’t figure out how to spend more 100$ a month on ML tools2, and this was worrisome. This is perhaps a strange framing, but here’s the reasoning: if you’re a highly-paid knowledge worker, if you could save hours per month by using AI tools, you should be jumping on every occasion to use them, and price them consequently. Here we are with the Library of Alexandria at our fingertips–albeit a stochastic one–for 20$ a month, and yet a lot of us will periodically cancel our subscriptions because we don’t actually use them. What’s going on?
The main ML tools have a huge discovery problem: it’s really hard to figure out what they can and can’t do. Using the tools is also a very private thing, so while your co-worker might have figured out a valuable workflow, you wouldn’t ever encounter it yourself unless you actively search for it. Workshops where people share their use cases and pain points are a great way to get up to speed.
In the absence of that, there are some great resources to learn about how to use AI tools and stay up-to-date:
Ethan Mollick’s blog. Ethan is a professor at the Wharton School at UPenn who has become something of an AI tools influencer. His bi-yearly summary of which tools bring the most value is always a great read.
Nicholas Carlini, How I use “AI”. A great, long blog post on different use cases for AI tools from the perspective of a software engineer. He shows the actual prompts he uses.
AI News. A daily AI-generated newsletter that tracks developments in AI tools, mostly LLMs. This one is highly technical, probably too in the weeds for most, but it’s a great way to catch up on the SOTA without digging into every last Reddit and Discord post.
Gotchas: there is a new tool that comes out every day. You can easily waste a lot of time testing out new tools that add marginal value. There are also marginal value AI influencers all over X and LinkedIn. It’s ok to lag behind in adoption by months.
Chat
There were many professors in the audience, so it comes as no surprise that chat tools that generate text were popular. The use cases are endless:
Summarize long documents
Help craft derived text, say, a tweeprint or a status report
Expand a list of bullet points into a proper email
Help battle the dragon that is Overleaf and its overfull hboxes
Catch grammatical mistakes and unclear sentences (especially relevant to people for whom English is a second or third language)
Give a high-level overview of a field, from which you can branch out
Get over the line when you’re just finishing a doc and need a fresh set of eyes on it; conversely, get you out of your head when you’re trying to write a first draft
One attendee mentioned an interesting mental model for chat models: they’re very good at style transfer. Taking text in one format and putting it into another format is really their forte. Now personally, I don’t always like the text that it generates in its house style, as it tends to be lifeless. I have the same qualms about Grammarly: sometimes, I do want to place redundant emphasis, create run-on sentences, and generally do all the things my high-school English teacher warned me not to do. As a rule, I don’t use chat tools (much) for blogging, because I want my blog posts to sound like me.

Chat tools go far beyond the humdrum use cases of automating the boring stuff, although their abilities can vary by tool. They don’t just do text-based tasks: paste in a screenshot or a PDF and it will generally do a good job of ingesting the content.
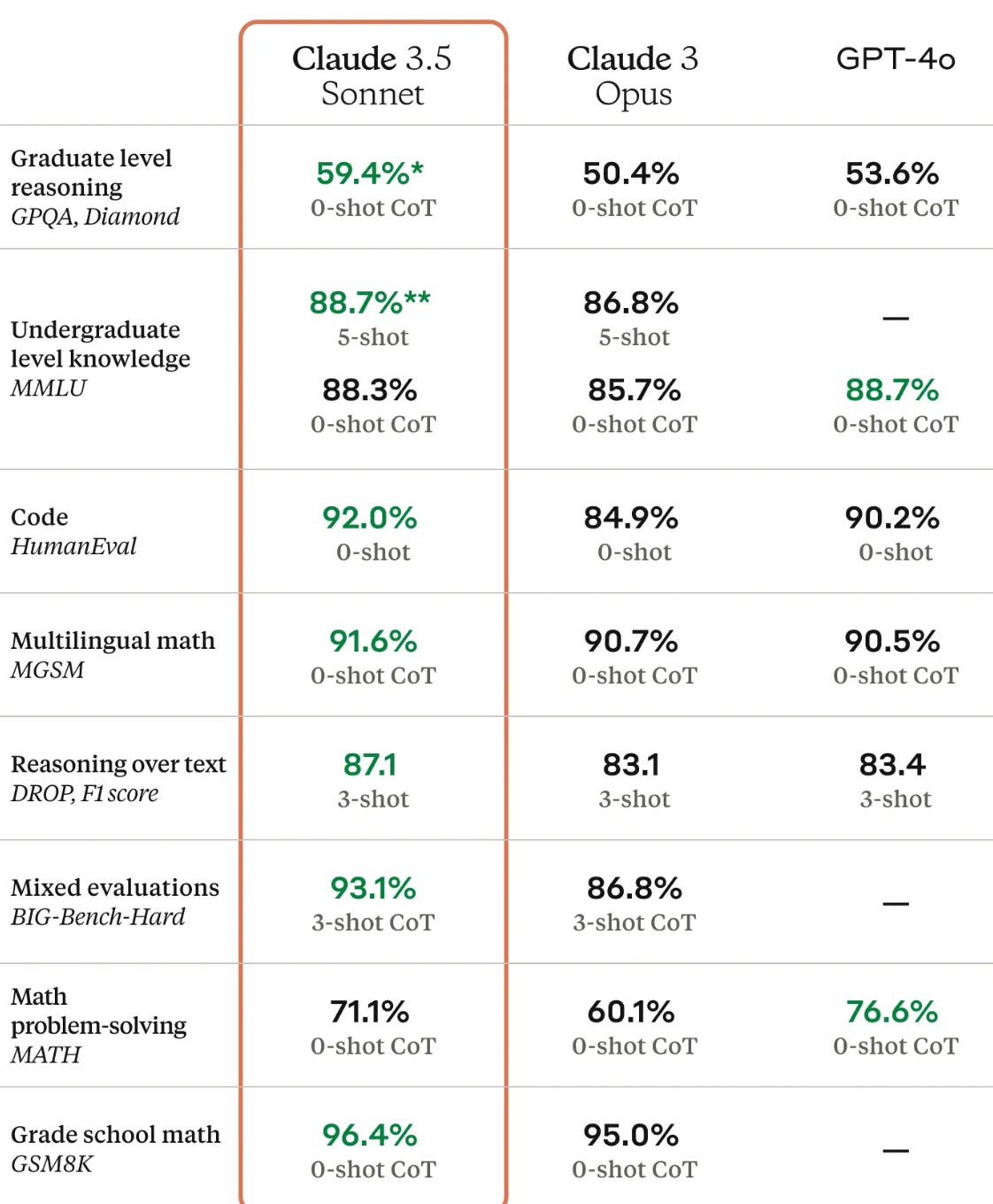
Here’s my rollup of useful general-purpose LLM tools:
Claude. My personal favorite, as I tend to prefer its style over ChatGPT’s–obviously, this is highly subjective. Excels at writing code. Again, worth the 20$/mo. This is my daily driver but I also pay for ChatGPT.
ChatGPT. A general-purpose tool for everyday use. Several people mentioned that o1-preview in particular excels at mathematical reasoning.
NotebookLM. Most known for its flashy podcast generation feature, an impressive gimmick whose sheen rapidly wears off. The real standout is its giant context window (2M tokens) and ability to cite references. You can throw in dozens of PDFs or several books worth, and it can do things like cross-referencing. Looking for a long PDF to try it on? How about our recent 92-page roadmap on NeuroAI safety?
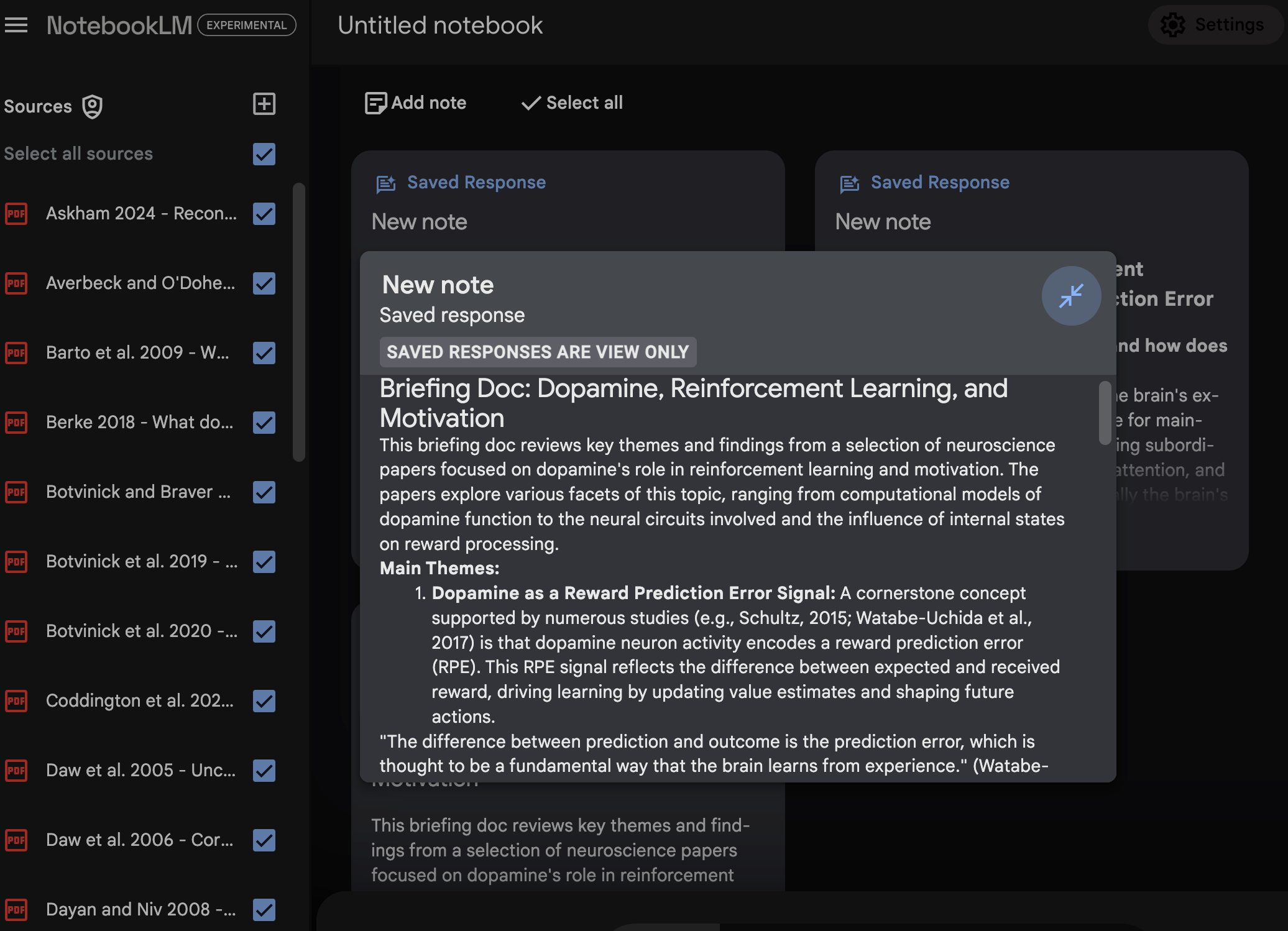
Gotchas: many tools allow the owner of the tool can train on you data. You should think twice about sharing private information with these tools, whether that’s unreviewed papers, private IP, or PII.
Aside: Audio as an interface to LLMs
Speech-to-text is a natural complement to LLMs. One very pragmatic use case is taking meeting notes. If you’re talking to a lot of people (we’ve talked with 100+ neuroscientists as part of building up the Enigma Project and then our NeuroAI safety roadmap), you’re going to take a lot of notes, which is boring but crucial work. I add Fireflies to all my meetings instead, and then interrogate the transcripts using an LLM.
I also use audio-to-text as a tool for thought. Sometimes I’ll read a paper and then record a conversation where I work out what I’ve understood from that paper. Or I’ll dictate an often rambling review for a conference paper and then ask an LLM to reformat it into a readable format. Audio untethers you from your laptop for deep thinking, allowing you to go on long walks and think through a problem.
Code
I led a section on coding tools. 80% of software engineers now use LLM tools, mostly Github Copilot, and Copilot is now a billion-dollar business. It is likely that PhD students and postdocs in your lab use them as well.
I use code tools all the time, mostly Copilot inside of VSCode, Claude, and occasionally Cursor. They have saved my butt more than a few times, with some prominent examples being:
I spent 3 weeks reviewing and editing all the code and text for all the tutorials for the NeuroAI course for Neuromatch. It was an absolute grind, and pretty high stakes given our hundreds of students. I would have not been able to make that much progress without Copilot inside of VSCode’s jupyter notebook environment.
I created a viral website ismy.blue to test your blue/green boundary and teach the general public about psychophysics of color perception. It received 2M visits and was covered in The Guardian and Wall Street Journal. I am not very proficient in HTML/JS, so this extended my reach.
I made a website with my co-author Joanne for our NeuroAI safety roadmap. It involved using pandoc to generate HTML from LaTeX, creating a dev server with live reload to test out the output, and doing a ton of CSS wrangling. Doing this manually would have been a huge pain.
While working on the NeuroAI safety roadmap, I made a strategic mistake: I drafted everything in Google Docs. Once I realized the paper was 3X longer than I originally intended and gdocs was slowing down to a crawl, I exported from gdocs to Word and then to LaTeX. Unfortunately, there was a lot of extra markup generated and the doc was slightly broken. Claude was fantastic at correcting the LaTeX markup.
I translated this app for a colorimeter from Matlab–for which I don’t have a license–to Python via Claude. This took a few minutes, whereas a manual effort would have taken a couple of days.
I showcased several use cases, including creating interactive visualizations from Python code, translating straight Python to Cython to obtain a massive 200X speed improvement in a leaky-integrate-and-fire simulation, and generating a skeleton for an adversarially robust MNIST classifier. Affordances for working with code are quite advanced compared to working with text:
you can use Copilot for autocomplete
you can interrogate an LLM in natural language from within your coding interface or in a sidebar
Claude’s artifacts and ChatGPT’s canvases give a specialized interface to write code and optionally preview it
Cursor can generate diffs and integrate them in your files
Code tools are very powerful, but they also create an opportunity to massively shoot yourself in the foot. The usual way you generate code in science is writing a little bit, testing it out, checking it looks good, and moving on. The tools generate too much code too fast for this to be an effective strategy, and can easily create tech debt traps.
For example, ismy.blue used a snippet of code to fit a psychometric curve (logistic regression). Because there’s no sci-kit equivalent in Javascript, I asked Claude to write it from scratch using Newton’s method. I’ve written this loop many times before in Matlab, and when I looked at it, it passed the sniff test, so I went ahead and copy-pasted it into the website code. Big mistake! It turns it didn’t check for convergence and about 5% of visitors to the site got the wrong boundary. The solution was a backtracking line search that should have been there from the get-go. If I had written the code from scratch, of course I would have written a backtracking line search. Argh!
The solution is defensive programming: write tests that check critical code sections for correctness. I have a short section on this idea on goodresearch.dev, which I hope to expand in the future.
Aside: writing code vs. mentoring
By default, LLMs will try to solve your problem directly. This can lead to become overly reliant on LLM code tools rather than developing proficiency. You can, however, prompt LLMs to give you mentoring and guidance rather than writing your code.
For instance, I’m learning Rust as part of Advent of Code, a holiday-themed daily coding challenge. On day 4, Advent Of Code’s question relates to solving a word search problem. I can ask Claude to directly solve the problem, and it will oblige:
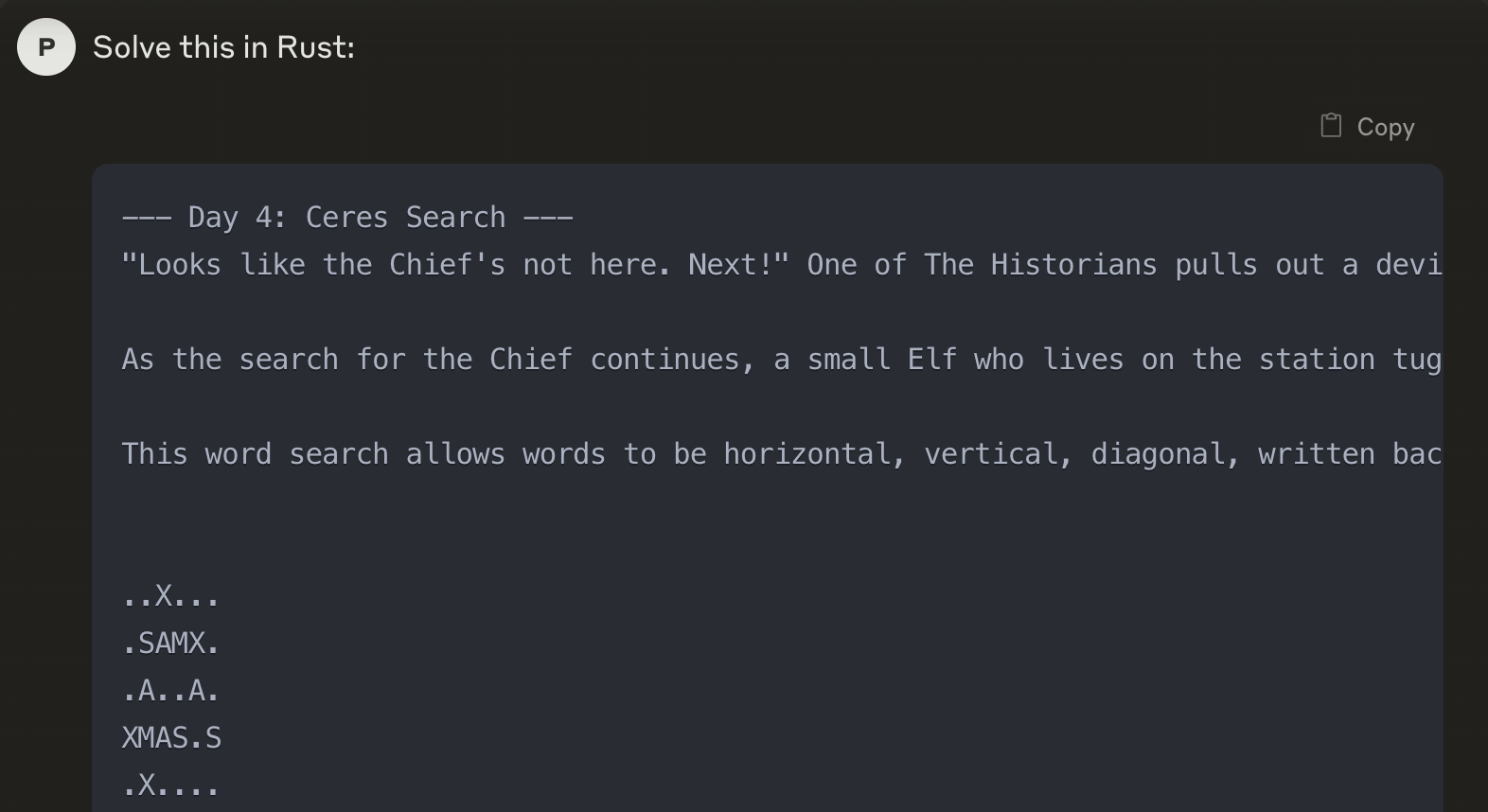
Then I can ask questions about its solution. In this case, it created a unit test using tags, a syntax I’m not familiar with. So I can dig in and find out why it did the things it did.

That’s certainly better than copying and pasting the code without thinking about it. However, I can go further by instead asking Claude to be a socratic tutor to help me solve the problem. Here’s one prompt that does the trick:
I am familiar with Python and JS and am attempting to learn Rust. I was a SWE at a FAANG and am familiar with data structures and algorithms. To learn Rust, I am doing daily exercises through the Advent of Code, a daily holiday-themed coding challenge. Help me guide my learning by asking questions in the style of a socratic tutor. Here’s today’s question: <question>
Instead of giving me the answer to the question, it prompts me to reflect:

I can then have a conversation with Claude and activately engage in the learning:

I can also give it broken implementations of code and help me better understand Rust’s syntax, or ask qualifying questions. This approach of “don’t give me the answer, give me the tools to answer the question myself” is useful beyond code: you can use that to decide which tack to take for a paper, a math proof, planning a conference, preparing for a meeting, etc.
Papers
Brad Love presented his paper on predicting neuroscience results using an LLM, an intriguing future use case that I’m excited for3. In the here and now, LLMs are already powerful enough for searching through papers and extracting structured information from them.
Probably one of the most useful everyday tools is Perplexity Pro. It’s an LLM-powered search engine. In Pro mode, you can set it so it searches from scholarly archives (i.e. Nature, arXiv, biorXiv, etc.). It only gives you about 8 or so references per query, but its hit rate is high, and it feels much better for freeform search than Google Scholar. I was skeptical of this tool, but it got high notes from Sam Rodriques from FutureHouse, which is building AI tools for scientists.
There is a slew of other tools for more specialized use cases. Elicit is a tool to facilitate structured searches, including metaanalyses. It can extract structured information on demand. Has Anyone is a tool from FutureHouse to determine whether something has ever been done. PaperQA2 is a FutureHouse agent-based model that can be used to do deep searches through literature.
It’s also possible to do searches using the raw models themselves for power users. I used this in our recent roadmap to estimate the rate of doubling in electrophysiology and calcium imaging capacity. I used the API version of GPT-4o to filter and parse through all 40,000 bioRxiv neuroscience abstracts, then ran the tool again to extract number of neurons, probes, model system, etc. This is monk’s work that would have taken many weeks of research assistant time, but that I was able to complete in about 3 days.

Unlike the case for code, it’s fair to say that the affordances for these tools still have a lot of gaps. For instance, I’d like to be able to search my paperpile library for relevant papers and dump it in NotebookLM. Simple enough, but right now I have to manually select relevant papers and download every single PDF before uploading to NotebookLM. Amelia Wattenberger showcased a tool to do search and download for arXiv for precisely this use case, which showed that UX tweaks could really make a large difference here. There is a lot more to be done in this space, and it seems clear that FutureHouse in particular is focused on making many of the existing tools more precise and usable.
Graphics
I feel like this may be the largest gap in the arsenal of ML tools for scientists. Dall-E’s house style sticks out like a sore thumb. Yes, you can get it to create good illustrations, but it still leaves a lot to be desired in terms of composition, aesthetics and accuracy. My gotos for generating illustrations for papers remains a combination of free icon libraries, stock photos, BioRender, Inkscape, LucidChart, Canva, tikz, etc.
The biggest issue is that I want to have fine control over aesthetics. Generated text is easily editable post-hoc. Images–not so much. What I really want is a vector image generation tool. This is slowly coming together. I tested out Illustrator’s new AI tools, and was able to generate a vector monkey with VR goggles that was editable and was not half bad.
Conclusion
It can be exhausting to keep track of all the latest advances in AI and how they impact your daily productivity. Nevertheless, adoption has been rapid. Code AI tools represent one of the most mature categories with some of the best affordances–Copilot was released before ChatGPT. Text tools are daily drivers that suffer from a lack of discoverability, which can be alleviated by sharing workflows with colleagues and reading blogs.
Tools to read and absorb papers are still in their infancy, but they could be transformative: WikiCrow is an automated system that generated 15,000 high-quality Wikipedia-style articles on human genes that lack one. Bad quality AI art is all too common, but an AI-first vector editing tool would be highly compelling. All in all, we have the ability to do things that sounded like science-fiction just a few years ago, but we need to be judicious in how we deploy these tools.
Before the BlueSky exodus.
It turns out you can spend 200$ a month on ChatGPT if you want.
Disclosure: I was one of the reviewers for this paper
Amazing set of resources and ideas! Thank you.