


NeuroAI paper roundup #4: neuro-inspired AI explanations
Could a neuroscientist understand an artificial neural net?

Let’s try a different NeuroAI paper roundup format this time: I’ll cover one paper in detail that really got me thinking, a second one more briefly, and I’ll link to several others which are conceptually related.
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning

Anthropic and the mechanistic interpretability team led by Chris Olah and Shan Carter have been working relentlessly to obtain mechanistic interpretations of deep neural networks. Some of their prior work decompose visual circuits in CNNs in ways that would make Hubel & Wiesel proud. There’s a lot of neuroscience inspiration in mechanistic interpretability, because neuroscientists have had a 50-year head start in finding ways of opening up the black box of (biological) neural networks. I really enjoyed this paper: it has some interesting ideas and lessons for neuroscientists interested in sparse vs. dense coding.
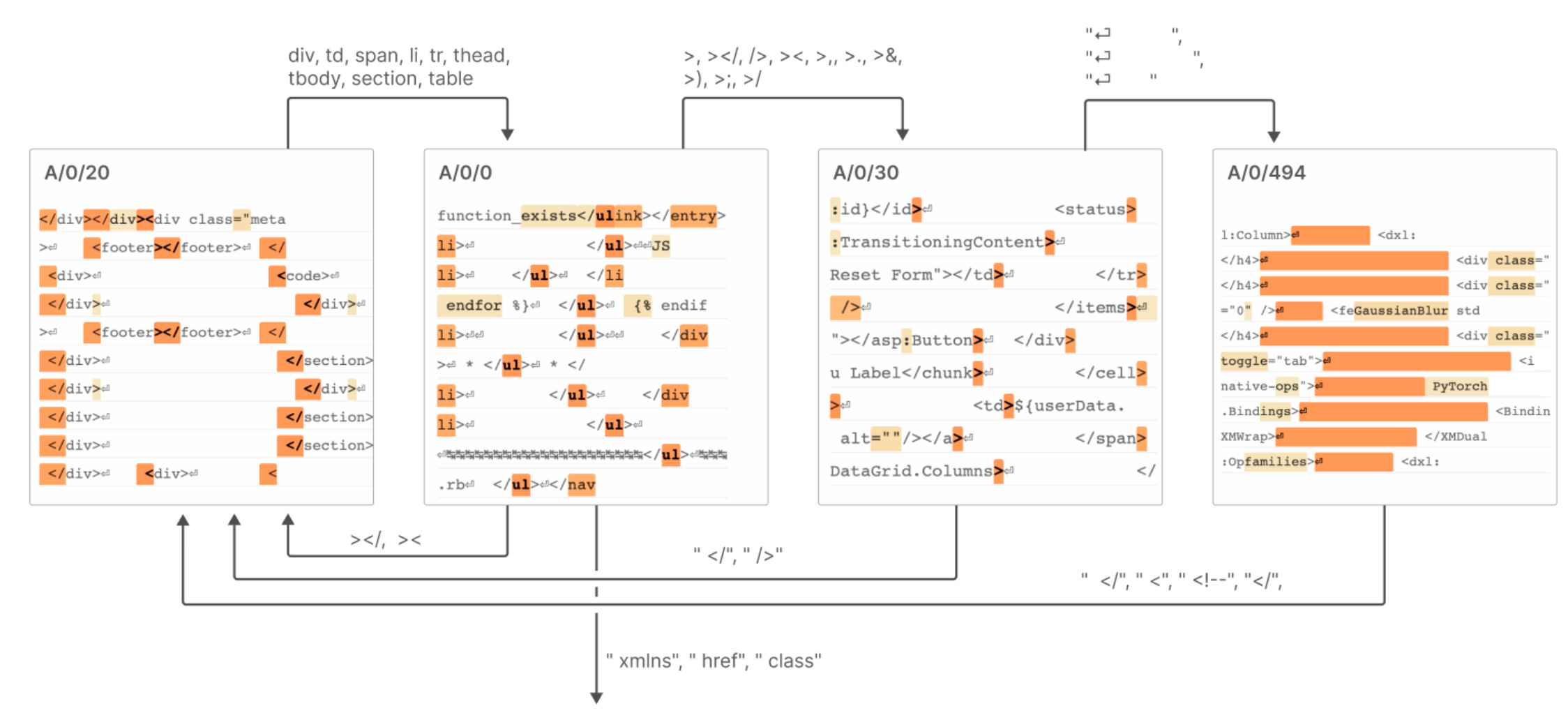
This work follows from an ongoing work thread on understanding transformers trained for natural language. Previously, they had found that a transformer trained on this task represents sequences densely. That means that a single neuron doesn’t have a lot of meaning, and there is no sense in which neurons form a privileged basis: a single neuron in the network is bafflingly hard to understand. It might participate equally in coding for base64, Arabic, rhyming patterns, etc. They previously proposed to resolve this by adding in a dash of sparse coding: adding a softmax in the middle of the transformer to force activations to be sparse. With this simple modification, they found that the single-neurons in the network were far easier to understand, with sparse coding causing representations to be disentangled.
This time, they threw out their old method in favour of a different way of implementing sparse coding. They realized that training one network directly with a sparse coding objective was unwieldy, and that things trained more stably with two networks. The first network learns to predict the next token, without constraints on the distribution of the neural activity; the second does a sparse coding decomposition of the MLP branch of the first. In terms of their actual implementation of sparse coding, it’s a two-layer MLP with an L1 loss that is trained in a supervised fashion, nothing too esoteric.

The directions found by the sparse coding algorithm are far more interpretable than the dense representation of the original network: units correspond to base64, Arabic, parts of HTML, etc. Furthermore, they find evidence of finite-state-machine-like representations, such that, e.g. they can trace the kinds of state tracked by the network as it autocompletes HTML strings.
Links to neuroscience
There’s a longstanding debate in neuroscience regarding sparse codes vs. dense codes. The last ten years have advanced the view that individual neurons don’t really matter; in one view, popular in motor neuroscience, neurons are random projections of the underlying dynamics (e.g. Gallego et al. 2017; Ebitz & Hayden 2021) .
I’m personally not fully on the side of reified dynamics–I think single neurons are important, which is mostly a reflection of my background as a visual neuroscientist rather than motor neuroscientist. Off-axis coding may be less efficient in biological neural networks as a consequence of the statistics of Poisson processes. I do think it’s been an important correction to the previous single-neuron-at-a-time view. Maybe the brain has figured out how to do (partial) sparse coding directly; or it may have mixed dense/sparse coding in the style of the two networks the Olah and co. Their work highlights that it’s not trivial to get sparse cording networks learning effectively, and we should spend some time as neuroscientists to investigate that.
On a more pragmatic note, I think we tend to fit toy models in neuroscience in the hopes that they will be interpretable. The team at Anthropic proposes a different approach–learn a giant and hopelessly complicated model that models the phenomenon perfectly; then learn a simpler model to explain the outputs of the complicated models. One advantage is that the complicated model can be infinitely probed. Indeed, they probe on billions of examples. The task of the second network–which distills the continuous outputs of the original outputs, similar to the problem of knowledge distillation–might be harder than the task of the original network. Splitting the problem in two untangles the two issues in an approachable way. Interestingly, their efforts show that they can extract information that looks a lot like neural ensembles and cellular assemblies. Perhaps the way to understand the language of the brain is to learn high-capacity proxy models which are then taken apart.
We see the filiation of this work from sparse coding neuroscience to AI; in fact, Bruno Olshausen is a reviewer of this paper. We could imagine that a lot more of the machinery to interpret biological neural networks could be useful going forward in mechanistic AI interpretability–from reverse correlation and multi-perturbation Shapley analysis to tensor component analysis.
Identifying Interpretable Visual Features in Artificial and Biological Neural Systems
An embedded problem in the previous paper is finding interpretable bases for complex data. They lucked out with sparse coding, but there’s no guarantee that sparse coding yields interpretable insights; it just so happens that in this case it does. Ultimately, “interpretable” can only be really understood in light of the limitations specific to the architecture of the human mind–although people have tried to find non-human-mind-linked measures of complexity, e.g. Kolmogorov complexity, they are intractable.

So how do you search basis space specifically for interpretable directions? Klindt, Sanborn and colleagues propose some interpretability metrics in visual classification networks based on color consistency, LPIPS and label consistency. Basically, a direction is interpretable if the images that maximize activity in that direction are visually similar. Given an interpretability metric, they can then evaluate a specific direction, picked from an off-the-shelf algorithm like PCA, K-means, ICA, sparse coding, etc. They’re able to use this to find some directions which are more interpretable in coding space.
Similar to the previous paper, they find that off-axis can be far more interpretable than on-axis directions (individual neurons). I think it’s a great start and a solid attempt at writing down a classifier for interpretable vs. non-interpretable. I do have some qualms about their choice of interpretability metric; taking a page from Kolmogorov complexity and minimum description length, it seems like “how hard it would be to communicate visual concept X using language” would be closer to what they’re getting at. It would interesting to reimplement the same idea using vision-language-model-based captioning + compression as the metric to optimize.
Related: Tim Lillicrap & Konrad Kording (2019) on what it means to understand a neural network.
Thanks to Sophia Sanborn for sending me the second paper. Got something interesting to share? Send me a message and I’ll try my best to cover it in an upcoming post.